1. Symbolic/Concept Learning & Version Space
1.1. Symbolic Learning
符号学习是一类归纳推理
- 演绎 (正向) 推理: $P\land (P\to Q)\Rightarrow Q$
- 反绎 (溯因/反向) 推理: $(Q\land (P\to Q))\to P$
- 归纳推理: $P\land (P\to Q)\not\Rightarrow Q$
1.2. Concept Learning
定义: 给定样例集合, 以及每个样例是否属于某个概念, 自动地推断出该概念的一般定义.
Formally, for
- a set of instances $X$,
- a target concept $c^*:X\to\{T, F\}$,
- training examples $D=\{(x_1, c^*(x_1)), (x_2, c^*(x_2)), \cdots, (x_m, c^*(x_m))\}$,
- a hypothesis set $H$ of functions, $\forall h\in H(h:X\to \{T,F\})$,
the concept learning problem is to find a hypothesis $h\in H$ such that
2. Inductive Bias
归纳偏置
归纳推理/机器学习不得不考虑下面的几个基本的问题:
- 目标概念假设不在假设空问怎么办?
- 能设计包含所有假设的空间吗?
- 假设空间大小对未见实例的泛化能力有什么影响?
- 假设空间大小对所需训练样例数量有什么影响?
3. ID3 Algorithm
3.1. Decision Tree Learning
实例:“属性-值”对表示,应用最广的)纳推理算法之一
,目标函数具有离散的输出值
,很好的健壮性(样例可以包含错误,也可以处理缺少属性值的实例)
丷能够学习析取表达式
口算法
V ID3, Assistant, C4.5
,搜索一个完整表示的假设空间,表示为多个Ifthen规则
口归纳偏置
,优先选择较小的树
Information Gain
我的这篇数据科学笔记记录了更多关于信息熵部分的知识
4. Other Tree Algorithms
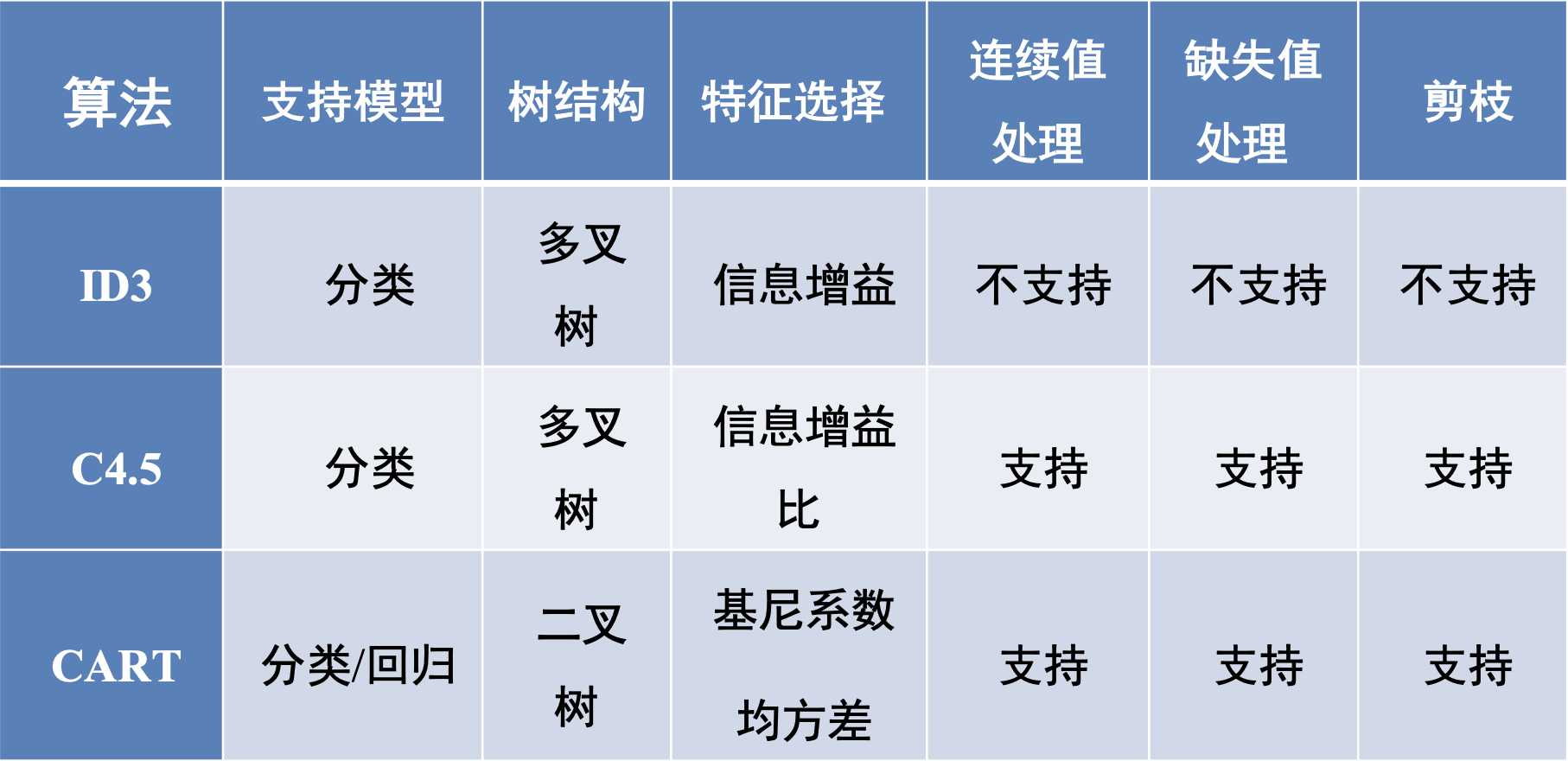
简单直观,生成的决策树很直观。相比于神经网络之类的黑盒分类模型,
决策树在逻辑上可以很好解释。
口基本不需要预处理,不需要提前归一化和处理缺失值。既可以处理离散值
也可以处理连续值。很多算法只是专注于离散值或者连续值。
口可以处理多维度输出的分类问题。
口使用决策树预测的代价是0(109211)。m为样本数。
口可以交叉验证的剪枝来选择模型,从而提高泛化能力。
口对于异常点的容错能力好,健壮性高。
树学习算法缺点
口树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本
数量和限制决策树深度来改进。
口决策树会因为样本发生一点的改动,导致树结构的剧烈改变。可以通过集
成学习之类的方法解决。
口寻找最优的决策树是一个NP难题,通过启发式方法,容易陷入局部最优。
可以通过集成学习的方法来改善。
口比较复杂的关系(如异或),决策树很难学习。一般这种关系只能用其他学
习方法(如神经网络)来解决。
口如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。可以通
过调节样本权重来改善。