1. Value of Relational Database
- 数据持久化: 大多数计算架构由两部分构成: 主存和后备存储器 (关系型数据库一般将持久化数据存储在后备存储器中)
- 支持并发: 关系型数据库提供了事务机制来控制对其数据的访问
- 集成: 使用共享数据库集成(shared database integration), 即多个应用程序都将数据保存在同一个数据库中.
- 近乎标准的模型: 数据模型, 事务的操作方式,
SQL方言在不同类型的关系数据库中基本是一样的
Relational database is fine, but not enough ~
2. NoSQL
NoSQL 简史
NoSQL一词最早出现于1998年, 是Carlo Strozzi开发的一个轻量, 开源, 不提供SQL功能的关系数据库.
2009年, Last.fm的Johan Oskarsson发起了一次关于分布式开源数据库的讨论[2], 来自Rackspace的Eric Evans再次提出了NoSQL的概念, 这时的NoSQL主要指非关系型, 分布式, 不提供ACID的数据库设计模式.
2009年在亚特兰大举行的"no:sql(east)“讨论会是一个里程碑, 其口号是"select fun, profit from real_world where relational=false;”. 因此, 对NoSQL最普遍的解释是"非关联型的", 强调Key-Value Stores和文档数据库的优点, 而不是单纯的反对RDBMS.
为什么要设计NoSQL
最大的原因是SQL不能解决我们遇到的全部问题.
阻抗失谐: 关系模型和内存中的数据结构之间存在差异
如果在内存中使用了较为丰富的数据结构, 那么要把它保存到磁盘之前, 必须先将其转换成“关系形式. 于是就发生了“阻抗失谐”: 需要在两种不同 的表示形式之间转译
解决办法
面向对象数据库
“对象-关系映射框架”( object-relational mapping framework) 通过映射模式 ( mapping pattern)表达转换
问题:
- 查询性能问题
- 集成问题
集成数据库
SQL充当了应用程序之间的一种集成机制. 数据库在这种情况下成了 “集成数据库”(integration database)
- 通常由不同团队所开发的多个应用程序, 将其数据存储在一个公用的数据 库中.
- 所有应用程序都在操作内容一致的持久数据, 提高了数据通信的效率
- 为了能将很多应用程序集成起来, 数据库的结构比单个应用程序所要用到 的结构复杂得多
- 如果某个应用程序想要修改存储的数据, 那么它就得和所有使用此数据库 的其他应用程序相协调.
- 各种应用程序的结构和性能要求不尽相同, 数据库通常不能任由应用程序 更新其数据. 为了保持数据库的完整性, 我们需要将这一责任交由数据库 自身负责.
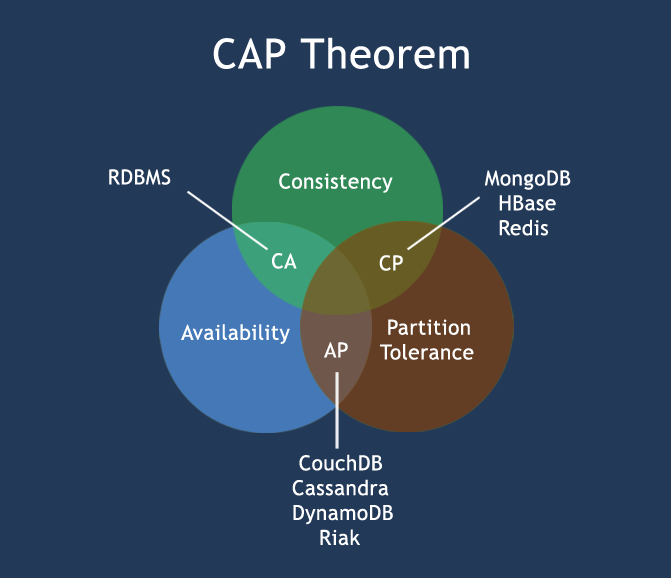
CAP定理 (CAP theorem)
在计算机科学中, CAP定理 (CAP theorem) , 又被称作 布鲁尔定理 (Brewer’s theorem) , 它指出对于一个分布式计算系统来说, 不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分区容错性(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是: 一个分布式系统不可能同时很好的满足一致性, 可用性和分区容错性这三个需求, 最多只能同时较好的满足两个.
因此, 根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则, 满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群, 满足一致性, 可用性的系统, 通常在可扩展性上不太强大.
- CP - 满足一致性, 分区容忍性的系统, 通常性能不是特别高.
- AP - 满足可用性, 分区容忍性的系统, 通常可能对一致性要求低一些.
3. Aggregate
4. NoSQL Data Schemas
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase Cassandra Hypertable |
顾名思义, 是按列存储数据的. 最大的特点是方便存储结构化和半结构化数据, 方便做数据压缩, 对针对某一列或者某几列的查询有非常大的IO优势. |
| 文档存储 | MongoDB CouchDB |
文档存储一般用类似json的格式存储, 存储的内容是文档型的. 这样也就有机会对某些字段建立索引, 实现关系数据库的某些功能. |
| key-value存储 | Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis |
可以通过key快速查询到其value. 一般来说, 存储不管value的格式, 照单全收. (Redis包含了其他功能) |
| 图存储 | Neo4J FlockDB |
图形关系的最佳存储. 使用传统关系数据库来解决的话性能低下, 而且设计使用不方便. |
| 对象存储 | db4o Versant |
通过类似面向对象语言的语法操作数据库, 通过对象的方式存取数据. |
| xml数据库 | Berkeley DB X ML BaseX |
高效的存储XML数据, 并支持XML的内部查询语法, 比如XQuery,Xpath. |
5. 分布式模型
6. 分布式模型中的一致性
7. 放宽‘“一致性”和“持久性”约束
8. 仲裁
9. 版本戳
10. 键值数据库
11. 文档数据库
12. 列族数据库
13. 图数据库
图数据库可存放实体及实体间关系. 在图数据库中, 实体是节点, 关系是有向边
用图将数据一次性组织好, 稍后便可根据“关系”以不同方式解读它.
图数据库有很多种, 如Neo4J, Infinite Graph, OrientDB和FlockDB 等 n FlockDB 是个特例, 它仅支持单深度的(single-depth)关系及邻接表 (adjacency list), 所以无法遍历深度超过1的关系
图数据库相对于关系型数据库的优势
图数据库中, 节点间可有多种不同 的关系类型, 由于节点关系的数量 及类型不限, 所以这些关系可存放 在同一图数据库中. 这样既能表现 领域实体(domain entity) 之间的关 系, 也可以表示辅助关系 ( secondary relationship) l 在图数据库中, 无需改变节点或边, 即可应对新的遍历需求. l 图数据库遍历“连接”及“关系”非常快. 节点间的关系不在查询时计算, 而 是在创建时已经持久化了. 遍历持 久化之后的关系, 要比每次查询时 都计算关系更快.
方向性(directionality) 有助于设计出丰富的领域模型. 可以根 据传入关系(INCOMING relationship)与传出关系(OUTGOING relationship) 双向遍历节点.
一致性
由于图数据库操作互相连接的节点, 所以大部分图数据库通常不支持把节点 分布在不同服务器上.
- 然而, Infinite Graph等某些解决方案, 可以把节点分布在集群中的服务器上.
在单服务器环境下, 数据总是一致的, 尤其是Neo4J这种完全兼容ACID事务 的(fully ACID-compliant)数据库.
如果在集群上运行Neo4J, 那么写入主节点的数据会逐渐同步至从节点, 而 读取操作则总是可在从节点执行. 也可以向从节点写入数据, 所写数据将立 刻同步至主节点, 但是其他从节点并不会立刻同步, 它们必须等待由主节点 传播过来的数据.
图数据库通过事务来保证“一致性”. 不允许出现“悬挂关系”(dangling relationship) :所有关系必须具备起始节点与终止节点, 而且在删除节点前, 必须先移除其上的关系.
事务
Neo4J是兼容ACID事务的数据库. 修改节点或向现有节点新增关系前, 必须先启动事务.
若未将操作包装在事务中, 则可能会抛出 NotInTransactionException.
- 先在数据库上发起事务, 然后创建节点并设置其属性. 接下 来, 将事务标注为success ( 成功), 最后调用finish方法完成 此事务. 事务必须标注为success, 否则Neo4J就假定它失 败了, 并会在执行finish时回滚. 仅设定success而不执行 finish,也会导致数据提交不到数据库
读取操作可不通过事务执行.
可用性
Neo4J支持“副本从节点”(replicated slave), 并借此获得较高的可用性.
- 这些从节点可处理写入请求:向其写入后, 它会先将所写数据同步 至当前主节点. 写入操作会先提交至主节点, 然后再提交至从节 点. 其他从节点将逐渐获得更新数据.
Infinite Graph与FlockDB等图数据库则支持分布式节点存储.
Neo4J使用Apache ZooKeeper来记录每个从节点及当前主节点中最新的事务ID. 服务器启动后, 将与ZooKeeper通信, 以 找出主服务器. 若该服务器第一个加入集群, 则它就成了主节 点. 当主节点故障时, 集群将在可用节点中新选主节点, 因此 极具可用性.