(1) A square matrix $P = ((p_{ij} ))_{i,j∈I}$ is called a $\textbf{stochastic matrix}$ if
(2) A square matrix $P$ is called a $\textbf{sub-stochastic matrix}$ if it satisfies $i.$ and $iii$
(3) A square matrix $P$ is called a $\textbf{doubly-stochastic matrix}$ if $P$ and $P^{\textsf T}$ are both stochastic matrices.
The way to think of the entry $p_{ij}$ is, roughly, “the probability of going to state $j$ next, given that we are at state $i$ now”. We will make this more precise, but for now think of these probabilities as “transition probabilities”. As such, a stochastic matrix is also commonly called a transition/Markov matrix, or a generator.
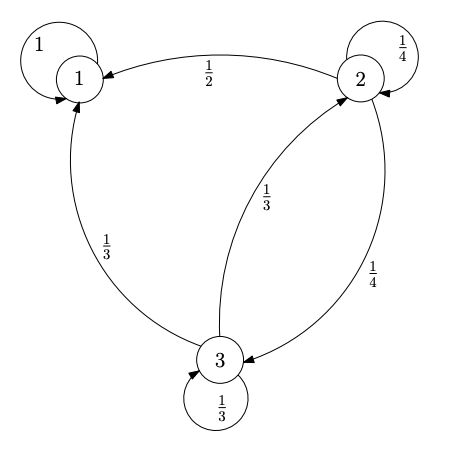
Given a Stochastic matrix $P = ((p_{ij} ))_{i,j∈I}$ we can define a weighed directed graph with vertex set I and edge weight of $(i, j)$ given by $p_{ij}$ . Note that, $\sum_{j∈I} p_{ij} = 1$ for all $i$ implies that the total weight of all the out-edges from the vertex $i$ is 1. The picture below shows the weighted direct graph of a the stochastic matrix
(1) A path in a directed graph $G = (V, E)$ is a collection of edges $(i_0, i_1), (i_1, i_2),\dots,(i_{n−1}, i_n)$ where $i_0, i_1,\ldots , i_n \in V$ . Moreover, the length of a path is the number of edges in this path, and the weight of a path is defined as
(2) A cycle is a path with the same starting and ending vertices.
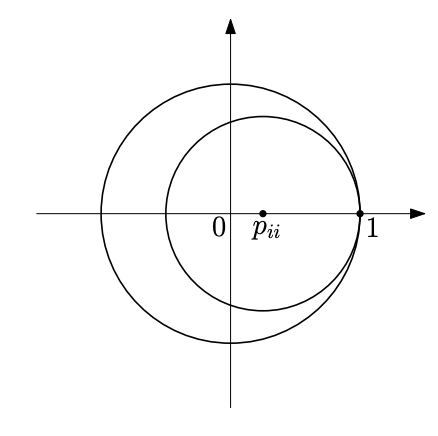
(i) $\operatorname{spec}(P) ⊆ B(0, 1)$
(ii) $\forall i:p_{ii} > 0\implies \operatorname{spec}(P) ⊆ B(0, 1) ∪ \{1\}$.
$Proof.$
i. $\forall i:R_i = \displaystyle \sum_{j\not =i} |p_{ij} | = 1 − p_{ii}$. Suppose $z$ is an eigenvalue of $P$. Then by $\textbf{Gershgorin circle theorem}$, $z ∈ B(p_{ii}, 1 − p{ii})$ and thus, $|z| ⩽ 1$.
ii. Follows from the fact that $B(p_{ii}, 1 − p_{ii}) ⊆ \overline{B(0, 1)} ∪ \{1\}$ if $p_{ii} > 0$. (as the folowing picture)
2. Discrete Time Markov Chains
2.1. Definitions
A stochastic process is a function of two variables, and could be written $X(ω, t)$. But it is more commonly written as $X_t(ω)$, since we think of these two variables differently. For each fixed $t ∈\mathcal T$, $X_t$ is a random variable, and once we choose a specific outcome in $Ω$, we have the number $X_t(ω)$. In this sense, a stochastic process is a sequence of random variables, indexed by time. On the other hand, for each fixed $ω ∈ Ω$, $X_t(ω)$ is a curve or path in the set $I$. So that we can think of a stochastic process as a random variable whose values are paths in $I$. Both of these points of view are valid and each will be useful in various contexts.
(1) $X_0\sim\lambda$, where $\lambda$ is the initial distribution
(2) $\mathbb P(X_n=j\mid X_0=x_0, X_1=x_1, \ldots,X_{n-1}=i=\mathbb P(X_n = j|X_{n−1} = i) = p_{ij})$, which implies, given $X_{n−1}$, the random number $X_n$ is independent of the history, $X_0, X_1, \ldots , X_{n−2}$.
Here, $P = ((p_{ij}))$ is called the transition matrix and we will use the notation
If $p_{ij}$ s are independent of time (consequently, transition matrix $P$ is also independent of time), then the Markov chain is called the $\textbf{time-homogeneous}$ Markov chain.
2.2. Examples
$\textbf{Random Walk on integers}$: Consider the set of integers and a Markov chain $(X_i)_{i⩾0}$. The random variables take integer values, $i.e.$ $I = \mathbb Z$. Consider $X_0 = 1$ (or some other distribution $\lambda$). The value of the random variable in the next step increases by 1 with probability 1/4, decreases by 1 with probability 1/4, and stays the same with probability 1/2. This can be formally written as
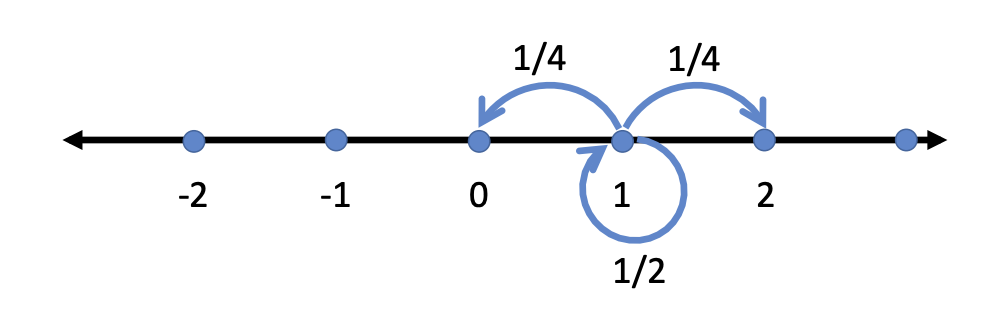
The transition probability matrix, $P$, has a special structure (tridiagonal matrix, 三对角矩阵) in this example
and we write, $(X_t)_{t⩾0} \sim \text{Markov}(\lambda, P)$. This process denoted as $(X_t)_{t⩾0} \sim \text{Markov}(\lambda, P)$, is also called $\textbf{Lazy Random Walk}$. It is called lazy since the Markov chain stays the same with a probability of 1/2.
$\textbf{Random Walk with absorption:}$ Consider an integer $n$ and a Markov chain $(X_t)_{t⩾0}$. The random variables take integer values in $I = \{−N, −(N − 1), \ldots , −1, 0, 1, . . . , N\}$. Consider $X_0 = 1$ (or some distribution $\lambda$). The value of the random variable in the next step increases by 1 with probability 1/4, decreases by 1 with probability 1/4, and stays the same with probability 1/2. Moreover, once the random variable reaches the end, $\{±N\}$, the random variable stays there with a probability of 1. We can write the transition probability matrix as,
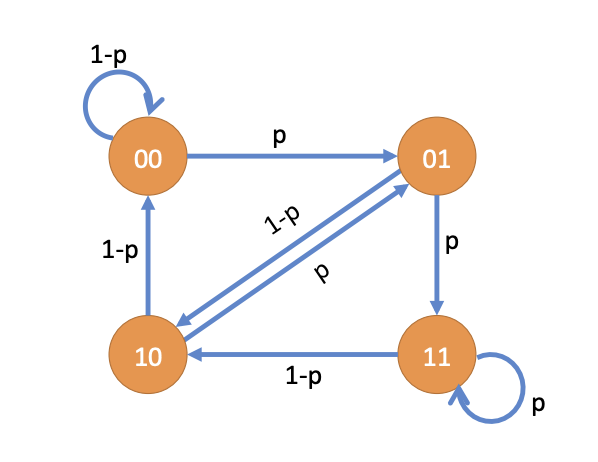
$\textbf{Pattern Recognition}$: Consider a sequence of $i.i.d.$ (独立同分布) $\text{Ber}(p)$ random variables $Y_t , t ⩾ 0$ where $Y_0$ takes value 1 with probability $p$ and takes value 0 with probability $1−p$. Now let us focus on finding the pattern $S = (1, 1)$, $i.e.$, the value of two successive random variables is 1. We consider new random variables $X_t$ defined as $X_0 = (Y_0, Y_1), X_1 = (Y_1, Y_2), \ldots , X_t = (Y_t , Y_{t+1}),\ldots$. The random variable $X_t$ takes values in set $I = \{(0, 0),(0, 1),(1, 0),(1, 1)\}$. The transition probabilities for $X$ can be written as,