1. Data Inconsistency
Three famous anatomies of inconsistency in a database system:
- 丢失修改 (Lost Update)
- 不可重复读 (Non-repeatable Read)
- 读 “脏” 数据 (Dirty Read)
Notations
R(x): 读数据xW(x): 写数据x
In order so solve these problems, we introduce the concept of Transaction.
A transaction is defined a s one or more operations which reflects a single real-world event.
- Happens completely or not at all
- The basic unit of recovery and concurrency control
1 | START TRANSACTION |
当用户没有显式地定义事务时, 数据库管理系统按 default 规定自动划分事务
-
事务正常结束
-
提交事务的所有操作 (读+更新)
-
事务中所有对数据库的更新写回到磁盘上的物理数据库中
-
事务异常终止
-
事务运行的过程中发生了故障, 不能继续执行
-
系统将事务中对数据库的所有已完成的操作全部撤销
-
事务滚回到开始时的状态
-
ACID properties of transactions
- Atomicity: 事务是数据库的逻辑工作单位. 事务中包括的诸操作要么都做, 要么都不做
- Consistency: 数据库中只包含成功事务提交的结果 (也就是说失败的事物必须rollback)
- Isolation: 一个事务的执行不能被其他事务干扰 (isolated), 并发执行的各个事务之间不能互相干扰
- Durability: 一个事务一旦提交, 它对数据库中数据的改变就应该是永久性的. 接下来的其他操作或故障不应该对其执行结果有任何影响
Question: How do we assure ACID?
- Logging and Recovery: guarantees atomicity and durability
- Concurrency Control: guarantees consistency and isolation, given atomicity.
2. Logging and Recovery
2.1. Faults
故障 (Fault) 的种类
- 事务内部的故障 (事务故障)
- 系统故障
- 介质故障
- 计算机病毒
各类故障, 对数据库的影响有两种可能性
- 数据库本身被破坏
- 数据库没有被破坏, 但数据可能不正确, 这是由于事务的运行被非正常终止造成的.
事务故障 指的是事务内部的故障, 是非预期的, 是不能由应用程序处理的, 包括:
- 运算溢出
- 并发事务发生死锁而被选中撤销该事务
- 违反了某些完整性限制而被终止等
事务故障的恢复: 事务撤消 (UNDO)
- 强行回滚 (
ROLLBACK) 该事务 - 撤销该事务已经作出的任何对数据库的修改, 使得该事务像根本没有启动一样
系统故障, 称为软故障, 是指造成系统停止运转的任何事件 (特定类型的硬件错误 (如CPU故障) , 操作系统故障, 数据库管理系统代码错误, 系统断 电) , 使得系统要重新启动.
- 整个系统的正常运行突然被破坏
- 所有正在运行的事务都非正常终止
- 不破坏数据库
- 内存中数据库缓冲区的信息全部丢失
介质故障, 称为硬故障, 指外存故障
- 磁盘损坏
- 磁头碰撞
- 瞬时强磁场干扰
介质故障破坏数据库或部分数据库, 并影响正在存取这部分数据的所有事务. 介质故障比前两类故障的可能性小得多, 但破坏性大得多.
病毒是数据库的主要威胁.
2.2. Recovery
Several key principles in recovery
- WAL (write-ahead log): a file that records every single action of all running transactions
- Force log entry to disk
- After a crash, transaction manager reads the log and finds out exactly what the transactions did or did not.
- Checkpointing: a DBMS may create checkpoints, which are snapshots of the database’s state
- Redo and Undo Operations:
- Redo operations involve reapplying logged changes that were not yet written to the database before a failure occured.
- Undo operations involve rolling back changes from transactions that were not yet committed at the time of failure.
Dumping: An example of checkpointing
转储 (dumping) 是指数据库管理员定期地将整个数据库复制到磁带, 磁盘或其他存储介质上保存起来的过程.
- 静态: 在系统中无运行事务时进行的转储操作
- 动态: 转储操作与用户事务并发进行
- 海量转储: 每次转储全部数据库
- 增量转储: 只转储上次转储后更新过的数据
Concurrency Control
Schedules
对于并发程序, 必须要考虑按照什么样的顺序进行调度.
- 串行调度(serial schedule)
- 可串行化调度(Serializability Schedule)
- 冲突 与 冲突可串行化调度
- 串行调度/可串行化调度/冲突可串行化调度 三者之间的关系
可串行化(Serializable)调度
多个事务的并发执行是正确的, 当且仅当其结 果与按某一次序串行地执行这些事务时的结果相同
冲突可串行化 (一个比可串行化更严格的条件)
冲突可串行化调度是可串行化调度的充分不必要条件
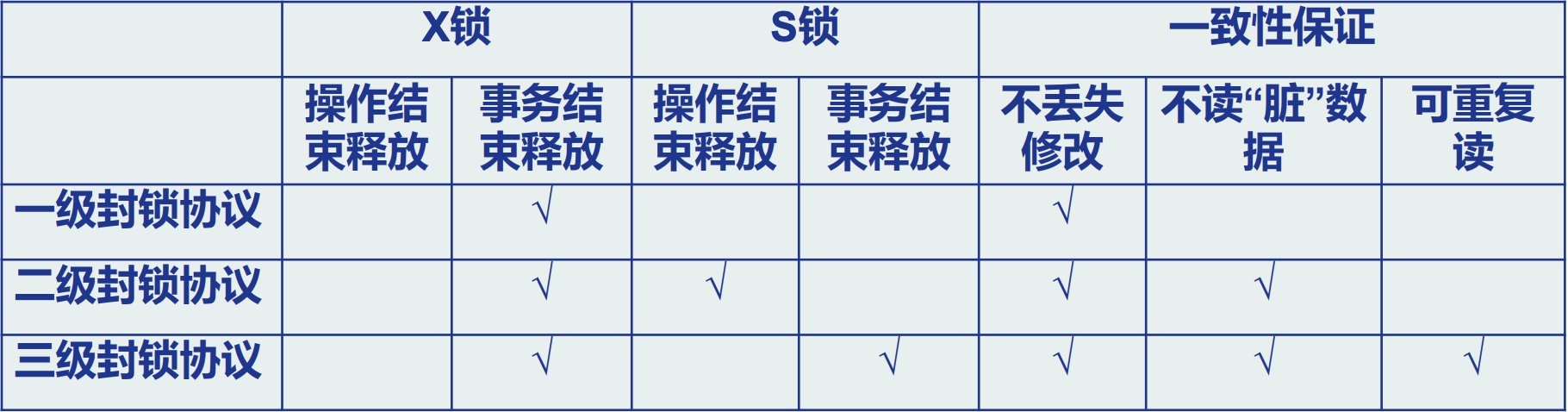
两段锁协议
指所有事务必须分两个阶段对数 据项加锁和解锁
遵守两段锁协议的调度一定是一个可串 行化调度.
数据库管理系统普遍采用两段锁协议的方法实 现并发调度的可串行性, 从而保证调度的正确性
两段锁协议, 指所有事务必须分两个阶段对数据项加锁和解锁
- 在对任何数据进行读, 写操作之前, 事务首先要获 得对该数据的封锁
- 在释放一个封锁之后, 事务不再申请和获得任何其 他封锁
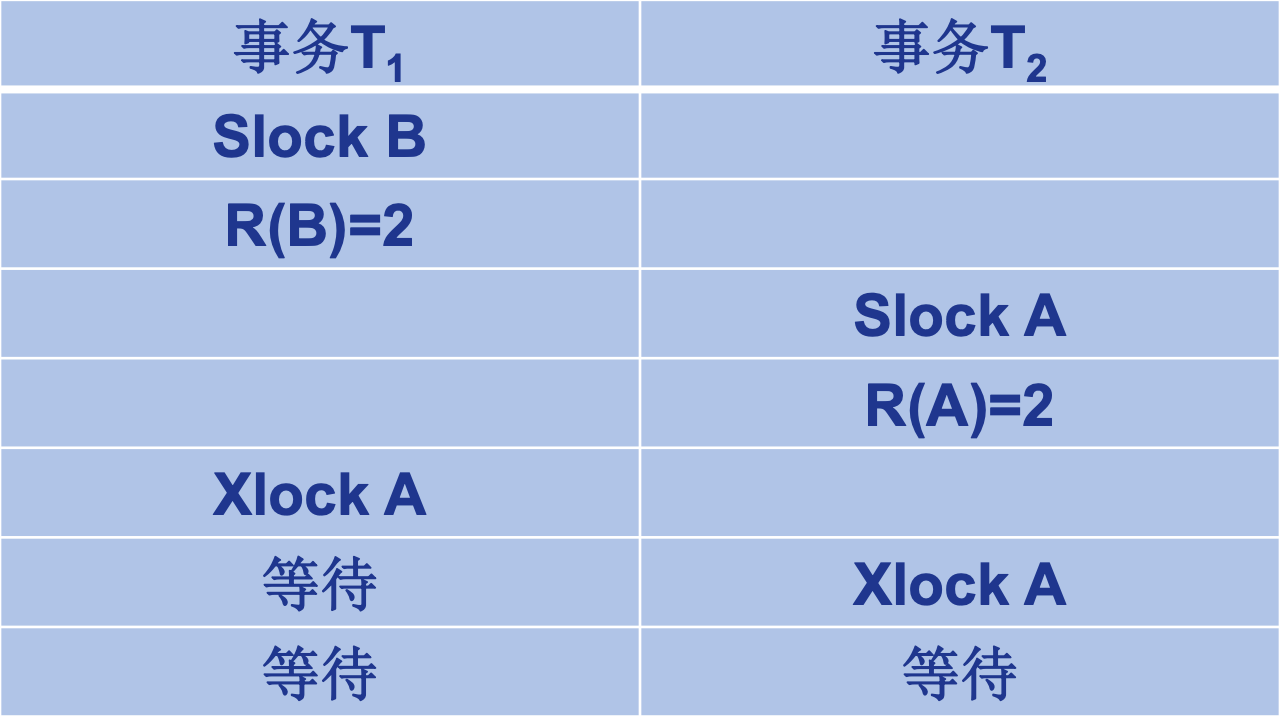
遵守两段锁协议的事务可能发生死锁
Locking
- 封锁(Locking)
- 时间戳(Timestamp)
- 乐观控制法
- 多版本并发控制(MVCC)
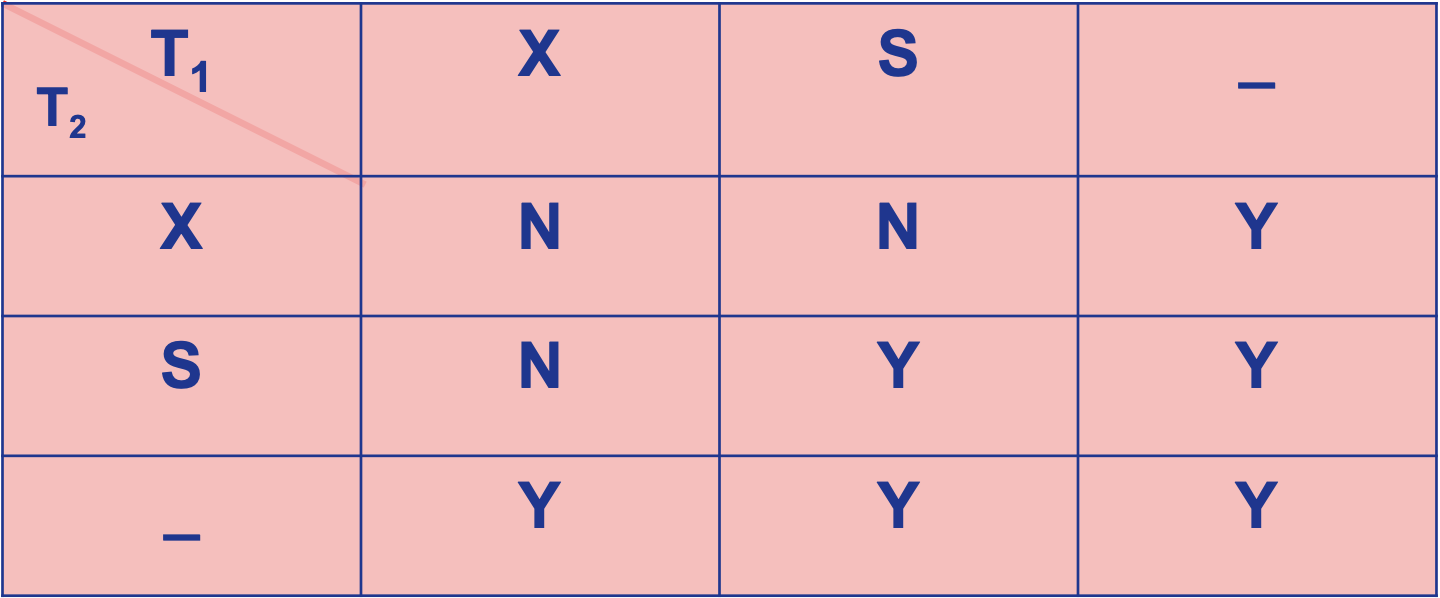
封锁:
排它锁 (Exclusive Locks, 简记为X锁)
- 共享锁 (Share Locks, 简记为S锁)
排它锁又称为写锁
- 若事务T对数据对象A加 上X锁, 则只允许T读取 和修改A, 其它任何事 务都不能再对A加任何 类型的锁, 直到T释放A 上的锁
- 保证其他事务在T释放A 上的锁之前不能再读取 和修改A
共享锁又称为读锁
-
若事务T对数据对象A加 上S锁, 则事务T可以读 A但不能修改A, 其它事 务只能再对A加S锁, 而 不能加X锁, 直到T释放 A上的S锁
-
保证其他事务可以读A, 但在T释放A上的S锁之 前不能对A做任何修改
在运用X锁和S锁对数据对象加锁时, 需要约定一些 规则, 这些规则为封锁协议 (Locking Protocol) .
- 何时申请 X 锁或 S 锁
- 持锁时间
- 何时释放
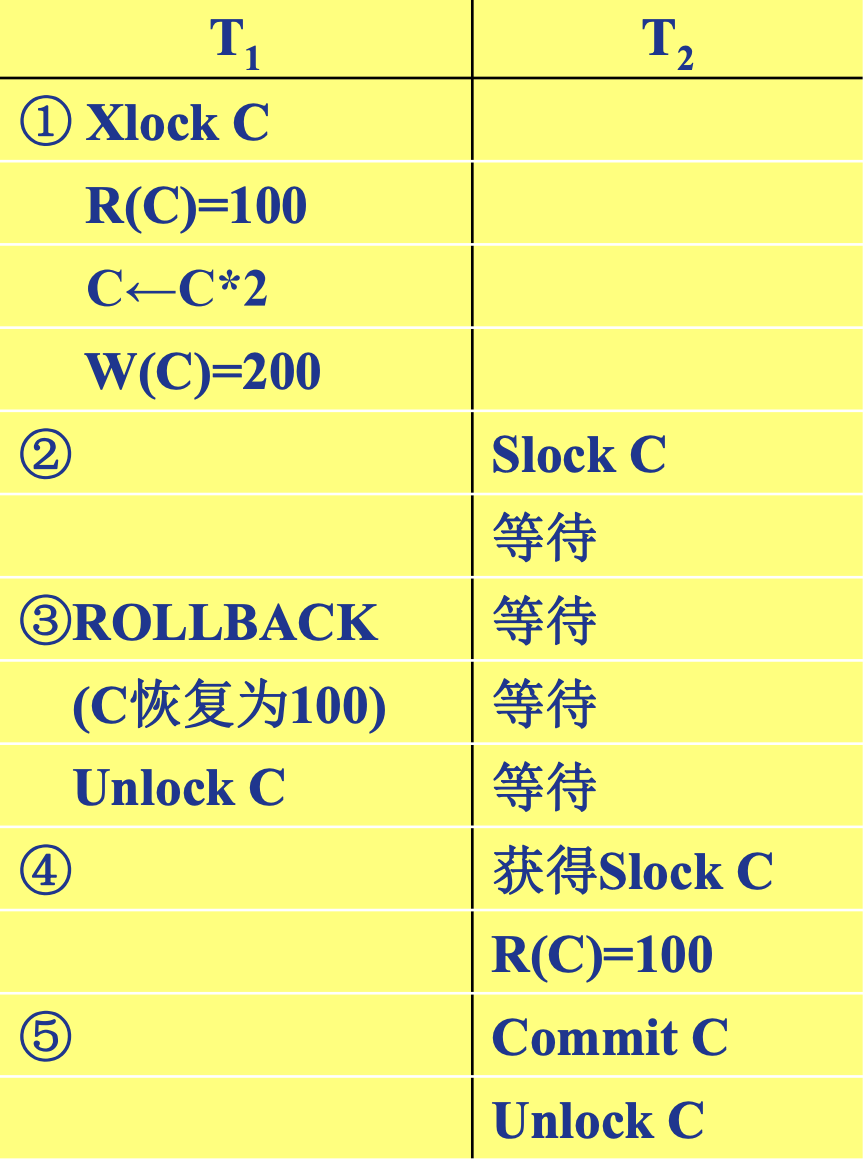
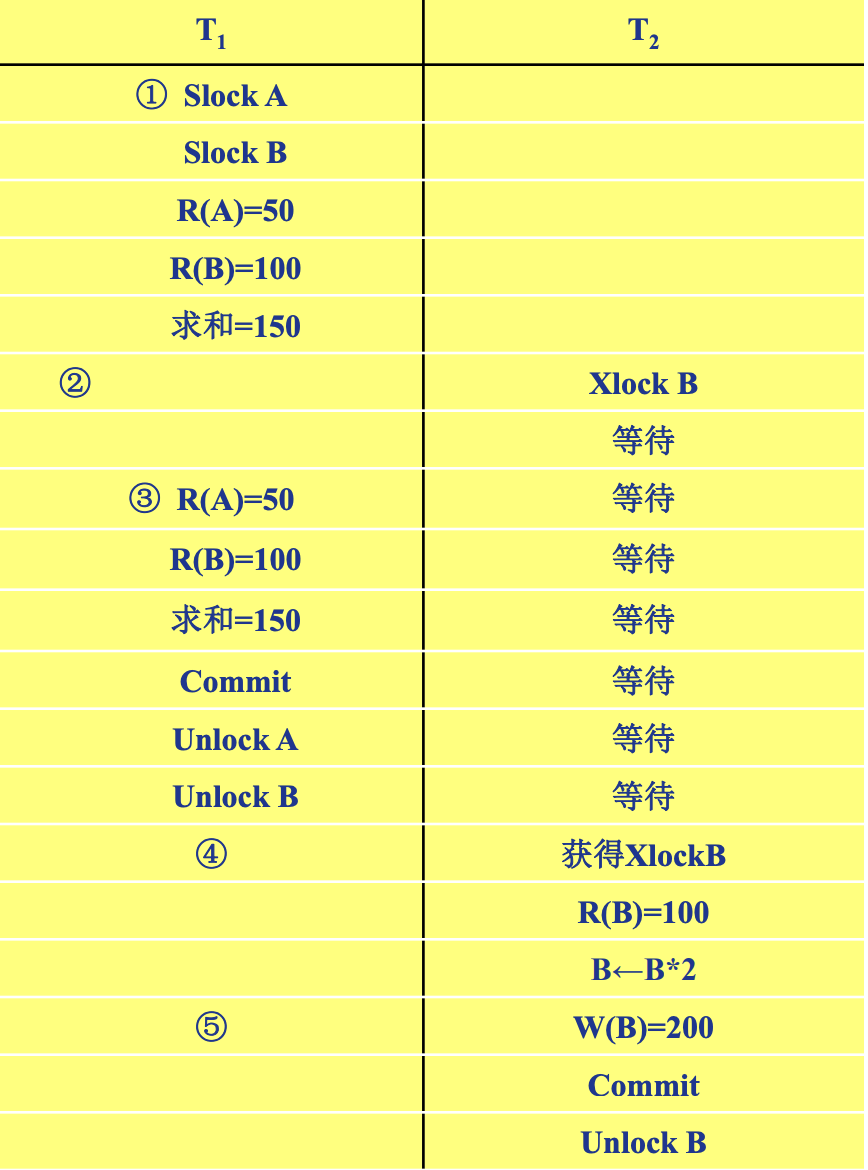
Starvation
避免活锁:采用先来先服务的策略
- 当多个事务请求封锁同一数据对象时
- 按请求封锁的先后次序对这些事务排队
- 该数据对象上的锁一旦释放, 首先批准申请队列中第一个事务获得锁
死锁
是两个或多个事务都已封锁了一些数据对象, 然后又都请求 对已为其他事务封锁的数据对象加锁, 从而出现死等待.
解除死锁
- 选择一个处理死锁代价最小的事务, 将其撤消
- 释放此事务持有的所有的锁, 使其它事务能继 续运行下去
Locking Granularity
多粒度封锁(Multiple Granularity Locking)
- 在一个系统中同时支持多种封锁粒度供不同的事务 选择
选择封锁粒度, 同时考虑封锁开销和并发度两 个因素, 适当选择封锁粒度
- 需要处理多个关系的大量元组的用户事务:以数据 库为封锁单位
- 需要处理大量元组的用户事务:以关系为封锁单元
- 只处理少量元组的用户事务:以元组为封锁单位
非常自然的设计
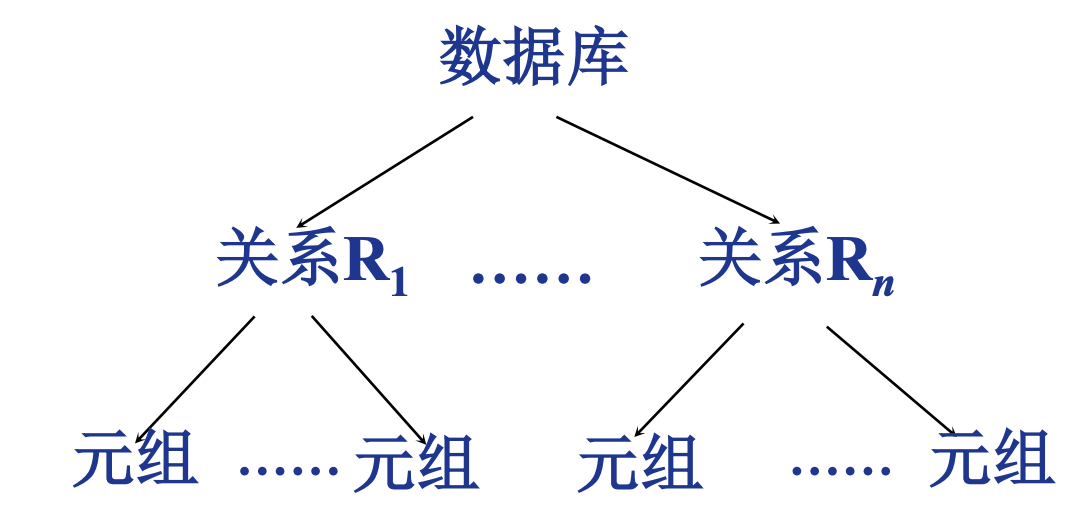
表示上, 可以用树形结构里表示不同粒度的locking
多粒度树
- 以树形结构来表示多级封锁粒度
- 根节点是整个数据库, 表示最大的数据粒度
- 叶节点表示最小的数据粒度
在多粒度封锁中一个数据对象可能以两种方式封锁:
- 显式封锁: 直接加到数据对象上的封锁
- 隐式封锁:是该数据对象没有独立加锁, 是由于其上级 节点加锁而使该数据对象加上了锁
显式封锁和隐式封锁的效果是一样的
对某个数据对象加锁, 系统要检查
-
该数据对象
- 有无显式封锁与之冲突
-
所有上级节点
- 检查本事务的显式封锁是否与该数据对象上的隐式封锁 冲突:(由上级节点已加的封锁造成的)
-
所有下级节点
- 看上面的显式封锁是否与本事务的隐式封锁 (将加到下 级节点的封锁) 冲突
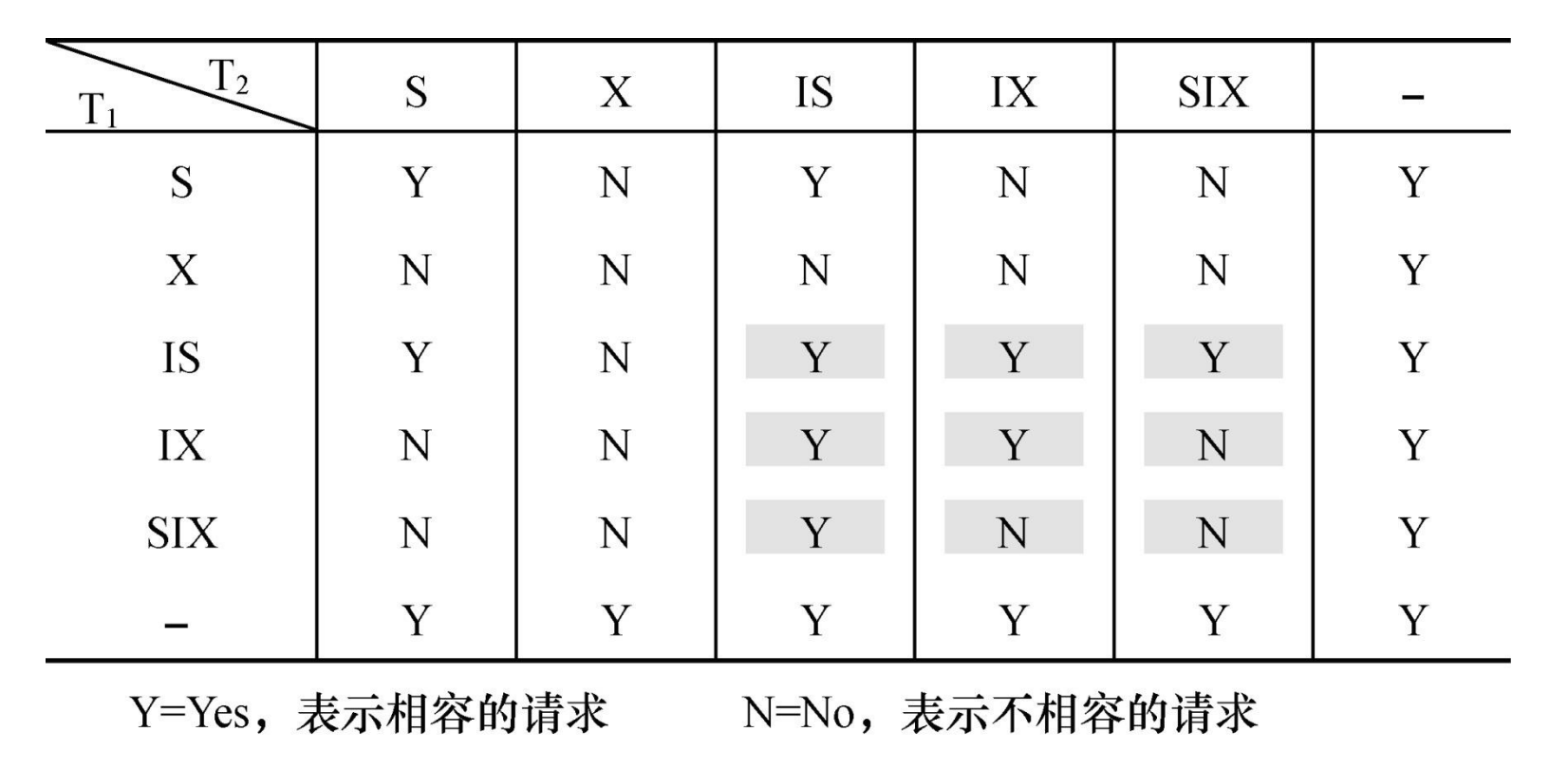
引入意向锁 (intention lock)
意向共享锁(Intent Share Lock, 简称IS锁)
- 如果对一个数据对象加IS锁, 表示它的后裔结 点拟 (意向) 加S锁.
- 例如:事务T1要对R1中某个元组加S锁, 则要 首先对关系R1和数据库加IS锁
意向排它锁(Intent Exclusive Lock, 简称IX 锁)
- 如果对一个数据对象加IX锁, 表示它的后裔结 点拟 (意向) 加X锁.
- 例如: 事务T1要对R1中某个元组加X锁, 则要 首先对关系R1和数据库加IX锁
Two-Phase Locking
-
封锁
-
排它锁的作用与申请规则
-
共享锁的作用与申请规则
-
-
两阶段封锁协议
-
死锁的定义
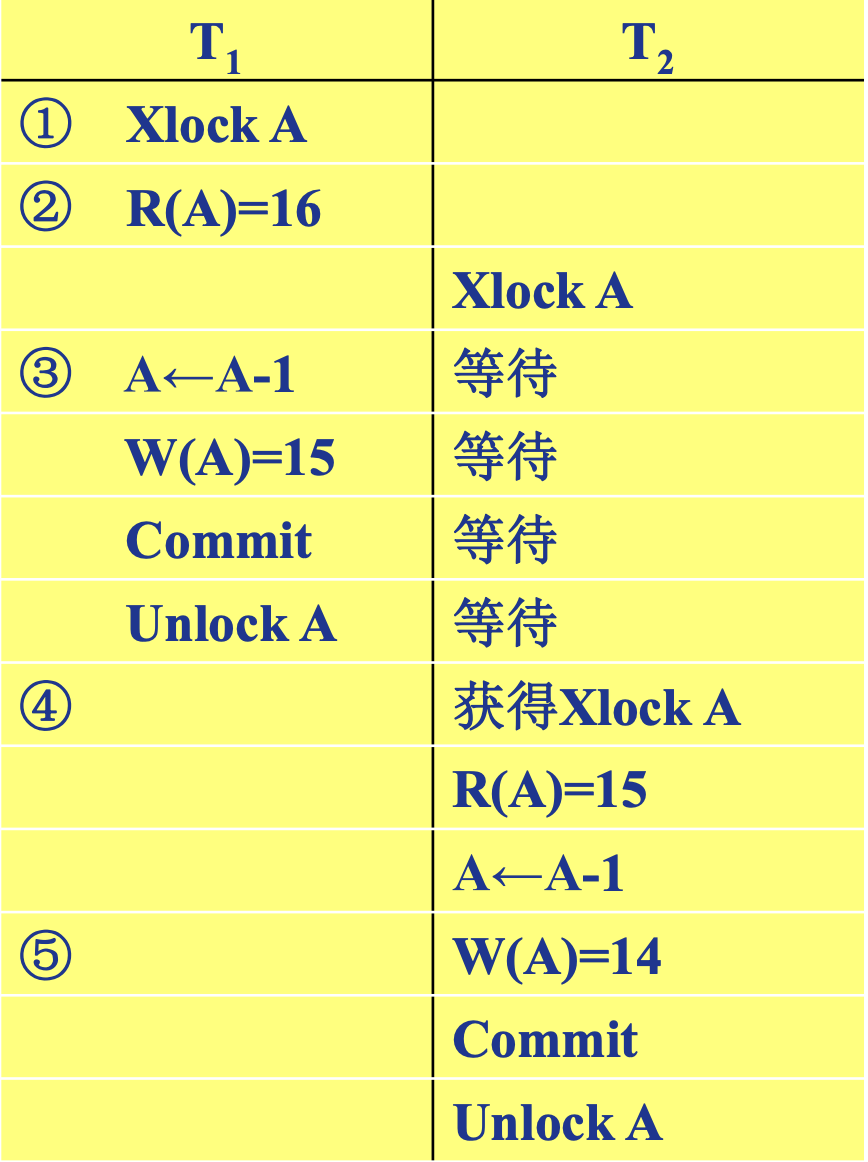
不可重复读包括三种情况, 后两种不可重复读有时也称为幻影现象 (Phantom Row) :
- 事务 $T_1$ 读取某一数据后, 事务 $T_2$ 对其做了修改, 当事务 $T_1$ 再次读该数据时, 得到与前一次不同的值
- 事务 $T_1$ 按一定条件从数据库中读取了某些数据记录后, 事务 $T_2$ 删除了其中部分记录, 当 $T_1$ 再次按相同条件读取数据时, 发现某些记录神秘地消失了.
- 事务 $T_1$ 按一定条件从数据库中读取某些数据记录后, 事务 $T_2$ 插入了一些记录, 当 $T_1$ 再次按相同条件读取数据时, 发现多了一些记录.
数据不一致性及并发控制
数据不一致性:由于并发操作破坏了事务的隔离性
并发控制就是要用正确的方式调度并发操作, 使一 个用户事务的执行不受其他事务的干扰, 从而避免 造成数据的不一致性
对数据库的应用有时允许某些不一致性, 例如有些 统计工作涉及数据量很大, 读到一些"脏"数据对统 计精度没什么影响, 可以降低对一致性的要求以减 少系统开销