这份笔记是用来记录数理逻辑的诸多定义和定理的, 以加强记忆. 所有的笔记都基于 A Mathematical Introduction to Logic
1. The Language of Sentential Logic
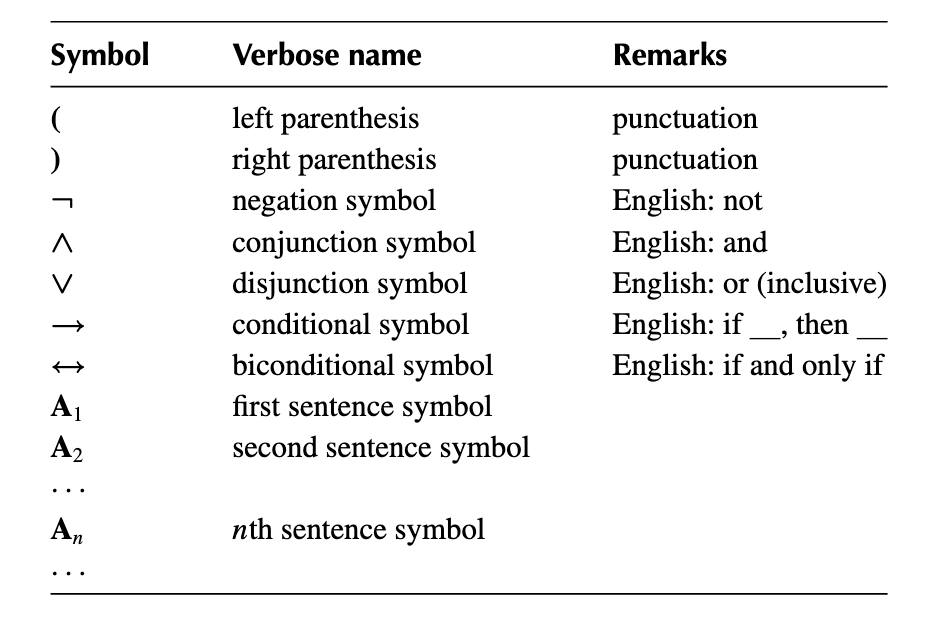
$def: \textbf{sentential connective symbols}$ (命题连接符)
The 5 symbols above are called sentential connective symbols.
$def:\textbf{logical symbols}$
logic symbols are sentential connective symbols and parentheses
$def: \textbf{Sentence Symbol}$
The sentence symbols which are often denoted as $\mathbf{A_n}$ are the parameters (or nonlogical symbols).
$def: \textbf{Proposition Symbol}$
Proposition (命题) is what a sentence asserts.
命题就是肯定语句, 命题逻辑就是语句逻辑
We have assumed that no symbol is a finite sequence of other symbols. The purpose of this assumption is to assure that finite sequences of symbols are uniquely decomposable.
$def: \textbf{Expression}$
An expression is a finite sequence of symbols.
$def: \textbf{Well-formed Formulas}$
We want to define the well-formed formulas (wffs) to be the
- Every sentence symbol is a wff.
- If $α$ and $β$ are wffs, then so are $(¬ α)$, $(α ∧ β)$, $(α ∨ β)$, $(α → β)$, and $(α ↔ β)$.
- No expression is a wff unless it is compelled to be one by (a) and (b).
More precisely, A well-formed formula (or simply formula or wff ) is an expression that can be built up from the sentence symbols by applying some finite number of times the formula-building operations (on expressions) defined by the equations:
$\textbf{INDUCTION PRINCIPLE}$
If $S$ is a set of wffs containing all the sentence symbols and closed under all five formula-building operations, then $S$ is the set of all wffs.
2. Truth Assignments
$def: \textbf{Truth Values}$
A truth values set is $\{T, F\}$, where
$def: \textbf{Truth Assignment}$
A truth assignment $v$ for a set $\mathcal S$ of sentence symbols is a function
assigning either $T$ or $F$ to each symbol in $\mathcal S$.
$def: \textbf{Extension Set \& Extension Assignment}$
Let $\mathcal {\bar S}$ be the set of wffs that can be built up from $\mathcal S$ by the five formula-building operations. ($\mathcal {\bar S}$ can also be characterized as the set of wffs whose sentence symbols are all in $\mathcal S$; see the remarks at the end of the preceding section.) We want an extension $\bar v$ of $v$,
that assigns the correct truth value to each wff in $\mathcal {\bar S}$. It should meet the following conditions:
- $\forall A ∈ \mathcal S: \bar v(A) = v(A)$. (这也是为什么叫扩展 [extension])
$\forall \alpha,\beta \in \bar \mS$:
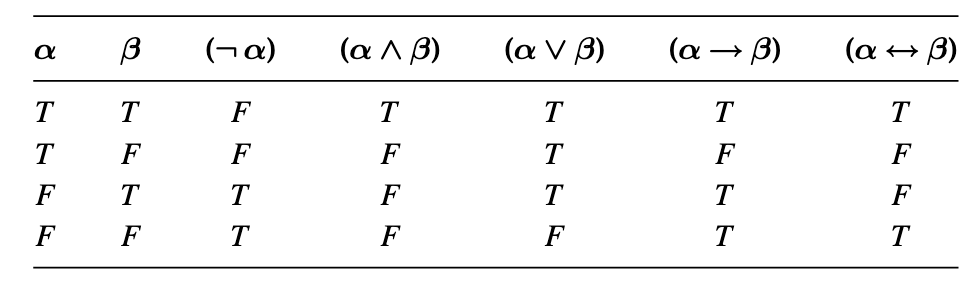
- $$\bar{v}((\neg \alpha))=\left\{\begin{array}{ll}T & \text { if } \bar{v}(\alpha)=F \\ F & \text { otherwise }\end{array}\right.$$
- $$\bar{v}((\alpha \wedge \beta))=\left\{\begin{array}{ll}T & \text { if } \quad \bar{v}(\alpha)=T \quad \text { and } \quad \bar{v}(\beta)=T \\ F & \text { otherwise. }\end{array}\right.$$
- $$\bar{v}((\alpha \vee \beta))=\left\{\begin{array}{ll}T & \text { if } \quad \bar{v}(\alpha)=T \quad \text { or } \quad \bar{v}(\beta)=T \text { (or both), } \\ F & \text { otherwise. }\end{array}\right.$$
- $$\bar{v}((\alpha \rightarrow \beta))=\left\{\begin{array}{ll}F & \text { if } \bar{v}(\alpha)=T \text { and } \bar{v}(\beta)=F, \\ T & \text { otherwise. }\end{array}\right.$$
- $$\bar{v}((\alpha \leftrightarrow \beta))=\left\{\begin{array}{ll}T & \text { if } \quad \bar{v}(\alpha)=\bar{v}(\beta) \\ F & \text { otherwise. }\end{array}\right.$$
$\textbf{THEOREM 12A}$
For any truth assignment $v$ for a set $S$ there is a unique function
f : U \times U \to U\ \text{ and }\ g : U → U
$$
Actually $\mathcal F$ need not be finite.
In defining the target subset $C$ more formally, we have our choice of two definitions.
-
We can define it
“ ” -
$def: \textbf{Closed}$
Say that a subset $S$ of $U$ is closed under $f$ and $g$ iff whenever elements $x$ and $y$ belong to $S$, then so also do $f(x, y)$ and $g(x)$. -
$def: \textbf{Inductive}$
Say that $S$ is inductive iff $B \subseteq S$ and $S$ is closed under $f$ and $g$.Let $C^*$ be the intersection of all the inductive subsets of $U$ ; thus $x ∈ C^*$ iff $x$ belongs to every inductive subset of $U$. It is not hard to see that $C^*$ is itself inductive. Furthermore, $C^*$ is the smallest such set, being included in all the other inductive sets.
-
-
The second (and equivalent) definition works
“ ”
We want $C_*$ to contain the things that can be reached from $B$ by applying $f$ and $g$ a finite number of times. Temporarily define a construction sequence to be a finite sequence $<span class="bd-box"><h-char class="bd bd-end"><h-inner>〈</h-inner></h-char></span>x_1, . . . , x_n<span class="bd-box"><h-char class="bd bd-beg"><h-inner>〉</h-inner></h-char></span>$ of elements of $U$ such that for each $i ≤ n$ we have at least one of$$\begin{array}{lll}x_{i} \in B & & \\ x_{i}=f\left(x_{j}, x_{k}\right) & \text { for some } & j<i, k<i \\ x_{i}=g\left(x_{j}\right) & \text { for some } & j<i\end{array} $$Then let $C_*$ be the set of all points $x$ such that some construction sequence ends with $x$. Let $C_n$ be the set of points $x$ such that some construction sequence of length $n$ ends with $x$. Then $C_1 = B$ and $\displaystyle C_* = \bigcup_n C_n$, where:
At this point we should verify that our two definitions are actually equivalent, i.e., that $C^* = C_*$ .
- $C^{*}\ {\subseteq}\ C_*$ : 由于 $C^*$ 是 $U$ 最小的归纳子集, 所以只要能证明到 $C_*$ is inductive.
- $C_{*}\ {\subseteq}\ C^*$ :
4.2. Recursion
5. Sentential Connectives
cont.