并发操作带来的数据不一致性
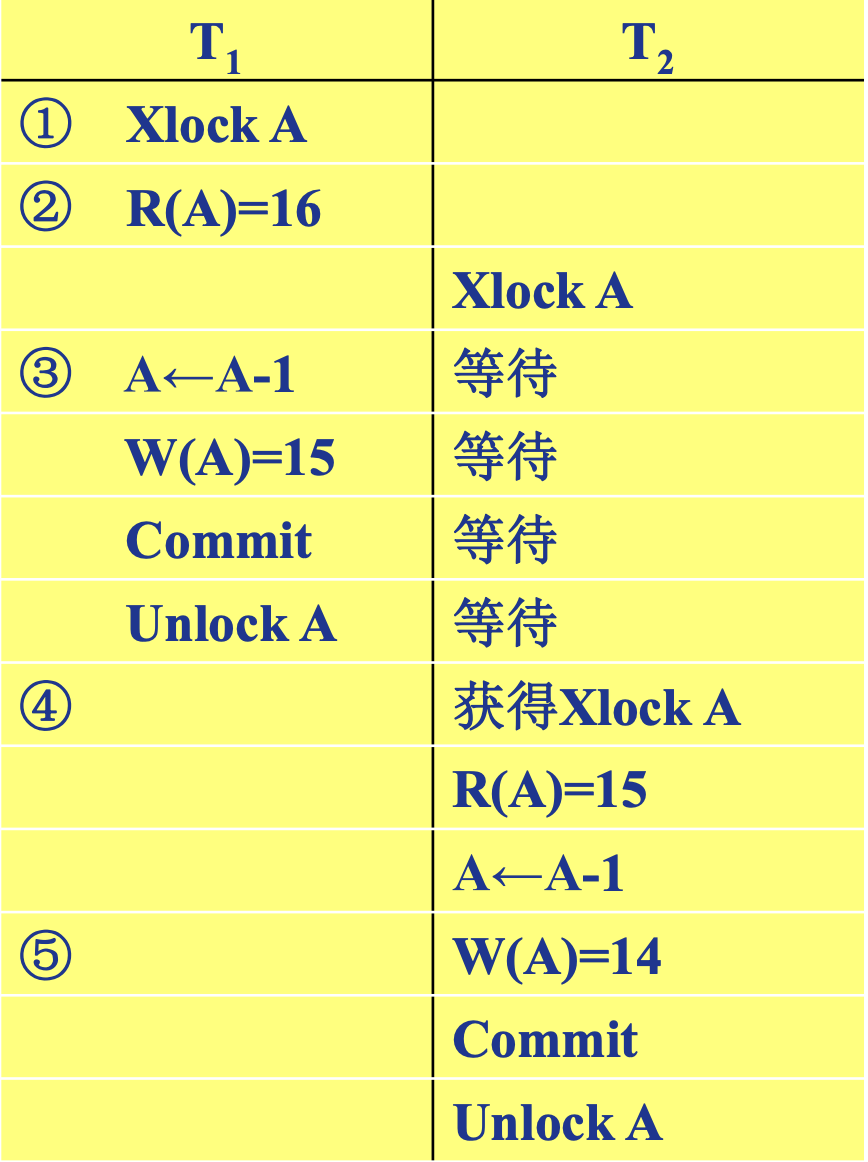
- 丢失修改
( ) - 不可重复读
( ) - 读
“ ” ( )
记号
- R(x):读数据x
- W(x):写数据x
不可重复读包括三种情况
数据不一致性及并发控制
数据不一致性
并发控制就是要用正确的方式调度并发操作
对数据库的应用有时允许某些不一致性
并发控制的主要技术
- 封锁(Locking)
- 时间戳(Timestamp)
- 乐观控制法
- 多版本并发控制(MVCC)
封锁:
排它锁
- 共享锁
( ,
排它锁又称为写锁
- 若事务T对数据对象A加 上X锁
, , , - 保证其他事务在T释放A 上的锁之前不能再读取 和修改A
共享锁又称为读锁
- 若事务T对数据对象A加 上S锁
, , , , - 保证其他事务可以读A
,
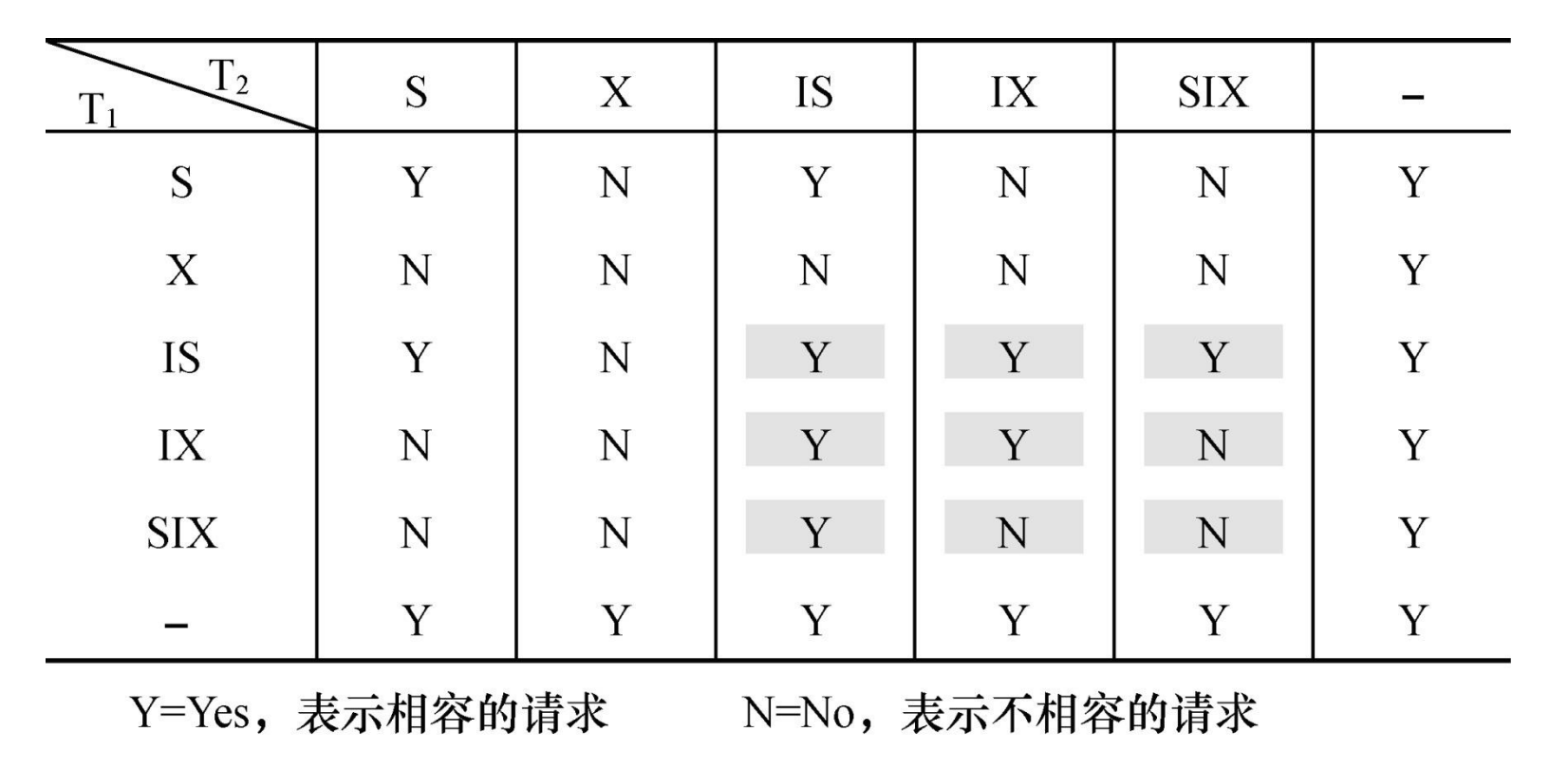
在运用X锁和S锁对数据对象加锁时
- 何时申请X锁或S锁
- 持锁时间
- 何时释放
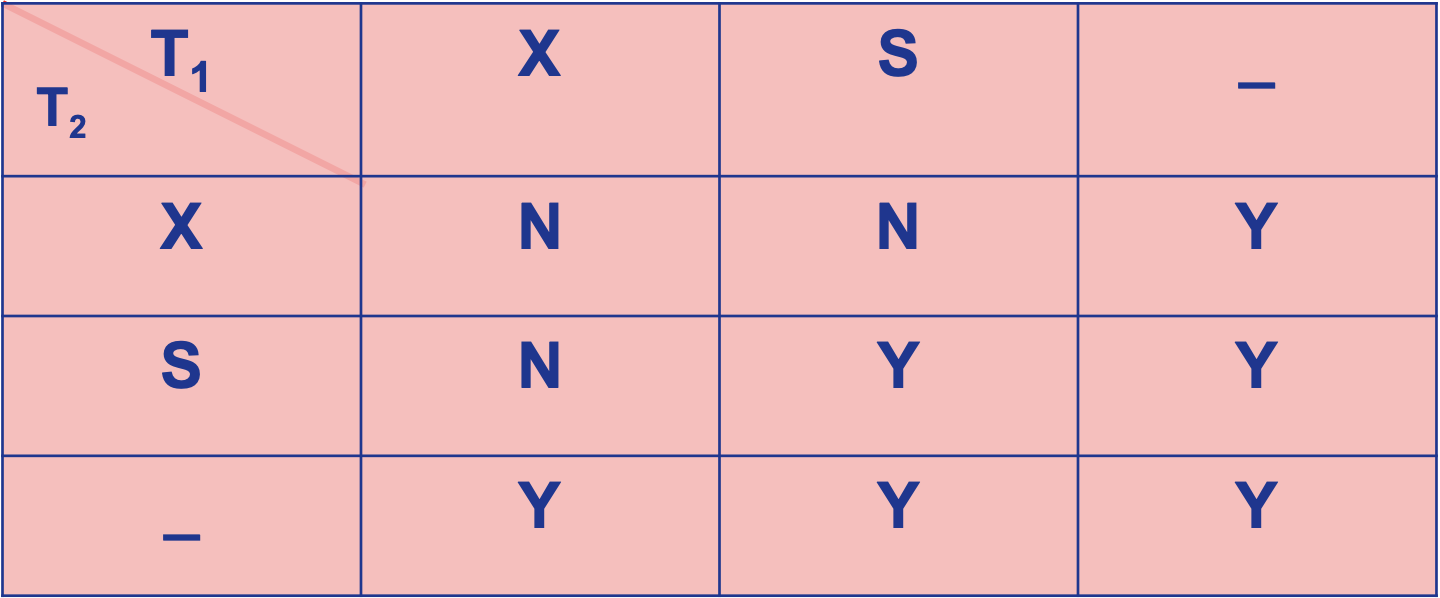
Starvation
避免活锁
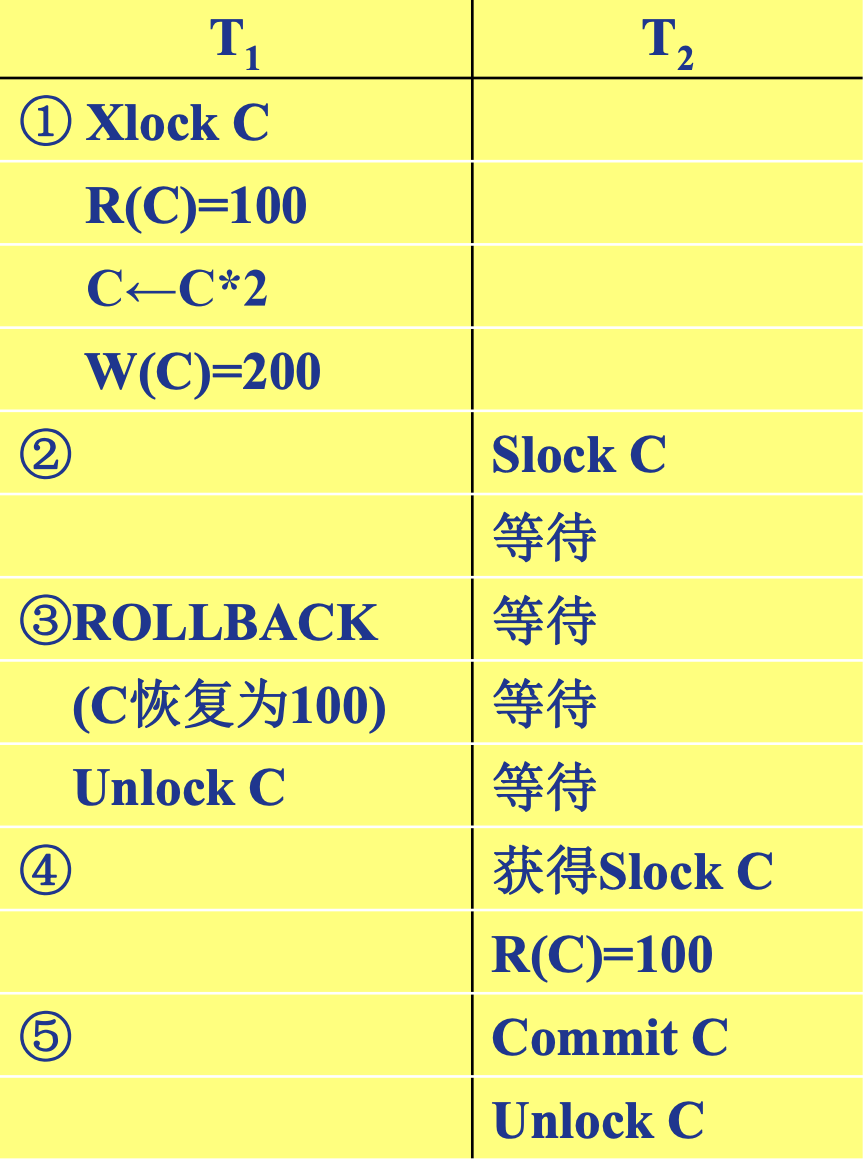
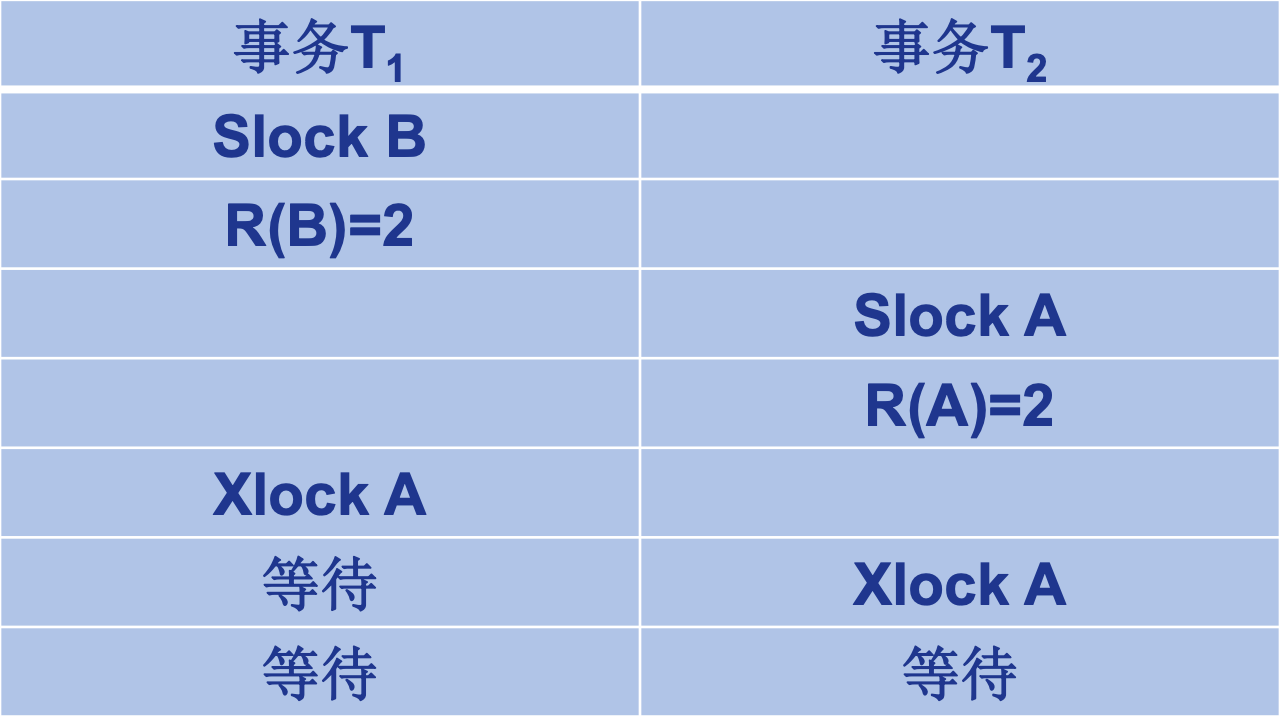
死锁
是两个或多个事务都已封锁了一些数据对象
解除死锁 ◼ 选择一个处理死锁代价最小的事务
Transaction Schedule
对于并发程序, 必须要考虑按照什么样的顺序进行调度.
可串行化(Serializable)调度
多个事务的并发执行是正确的
冲突可串行化 (一个比可串行化更严格的条件)
冲突可串行化调度是可串行化调度的充分不必要条件
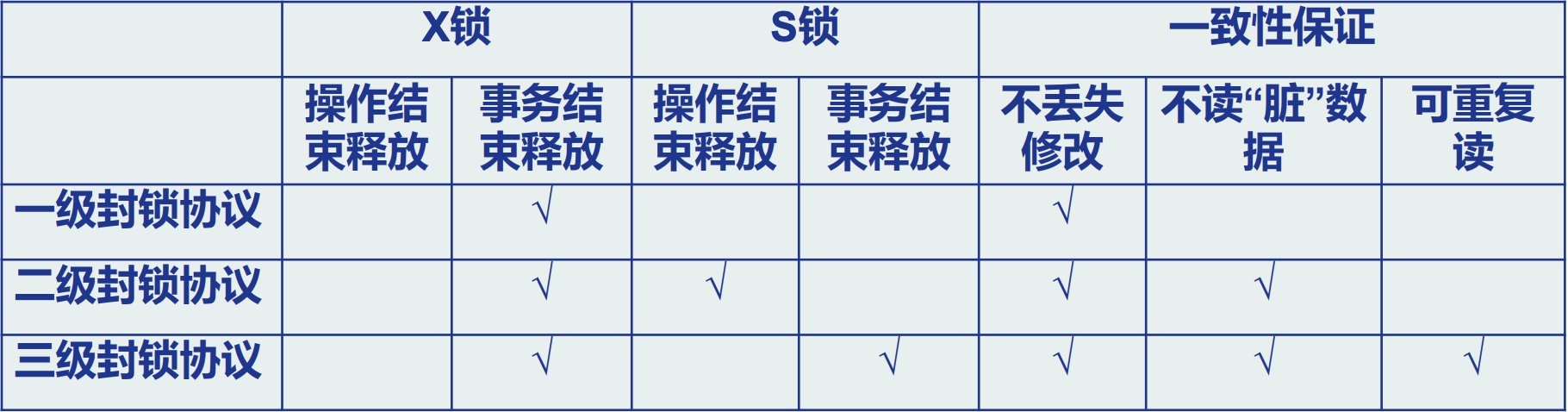
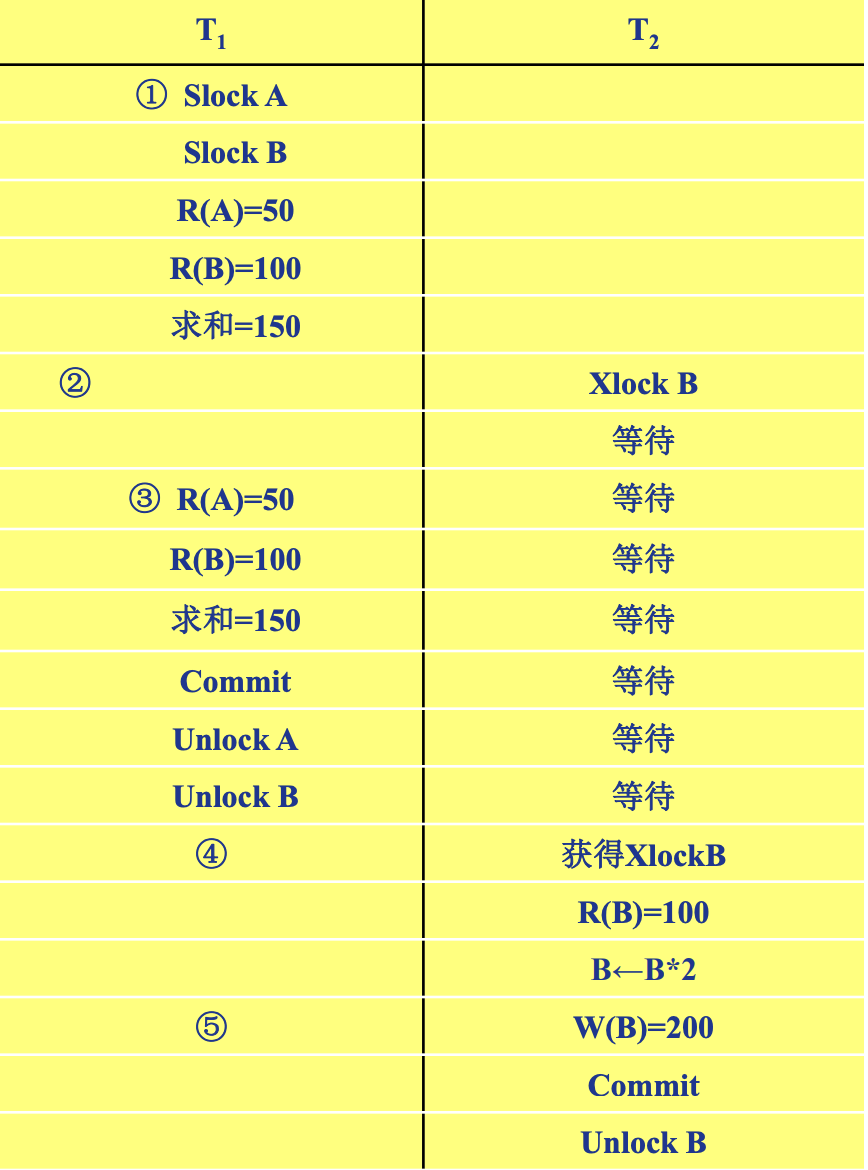
两段锁协议
指所有事务必须分两个阶段对数 据项加锁和解锁
遵守两段锁协议的调度一定是一个可串 行化调度
数据库管理系统普遍采用两段锁协议的方法实 现并发调度的可串行性
两段锁协议
- 在对任何数据进行读
、 , - 在释放一个封锁之后
,
遵守两段锁协议的事务可能发生死锁
Locking Granularity
多粒度封锁(Multiple Granularity Locking)
- 在一个系统中同时支持多种封锁粒度供不同的事务 选择
选择封锁粒度
- 需要处理多个关系的大量元组的用户事务
: - 需要处理大量元组的用户事务
: - 只处理少量元组的用户事务
:
非常自然的设计
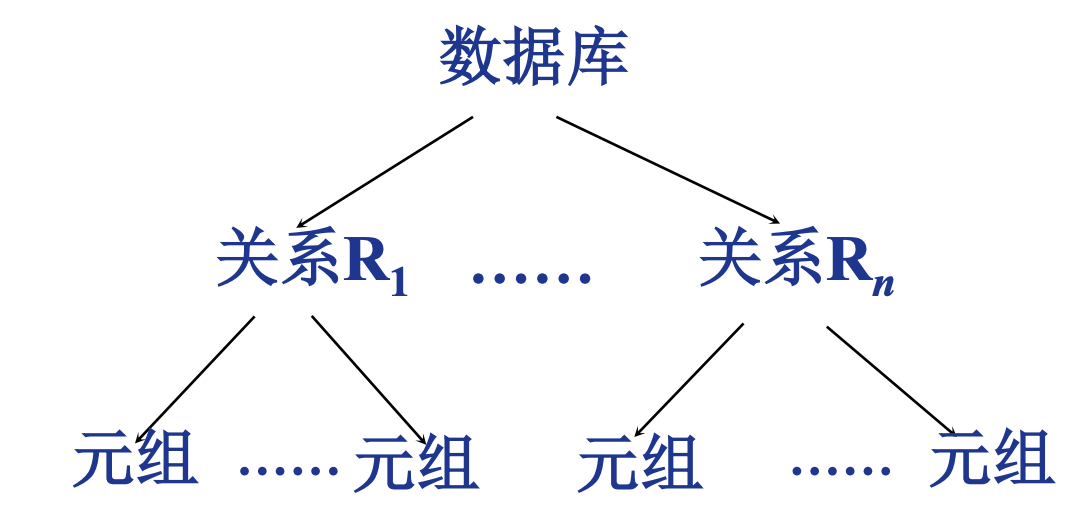
表示上, 可以用树形结构里表示不同粒度的locking
多粒度树
- 以树形结构来表示多级封锁粒度
- 根结点是整个数据库
, - 叶结点表示最小的数据粒度
在多粒度封锁中一个数据对象可能以两种方式封锁
- 显式封锁: 直接加到数据对象上的封锁
- 隐式封锁:是该数据对象没有独立加锁
,
显式封锁和隐式封锁的效果是一样的
对某个数据对象加锁
-
该数据对象
- 有无显式封锁与之冲突
-
所有上级结点
- 检查本事务的显式封锁是否与该数据对象上的隐式封锁 冲突
: )
- 检查本事务的显式封锁是否与该数据对象上的隐式封锁 冲突
-
所有下级结点
- 看上面的显式封锁是否与本事务的隐式封锁
( )
- 看上面的显式封锁是否与本事务的隐式封锁
引入意向锁 (intention lock)
意向共享锁(Intent Share Lock
- 如果对一个数据对象加IS锁
, ( ) 。 - 例如
: ,
意向排它锁(Intent Exclusive Lock
- 如果对一个数据对象加IX锁
, ( ) 。 - 例如
: ,