1. 文件系统
1.1. 文件
1.2. 文件系统
操作系统中负责存取和管理信息的模块
观察文件, 需要观察它的两个部分
- 逻辑结构 (逻辑文件)
- 存储结构 (物理文件)
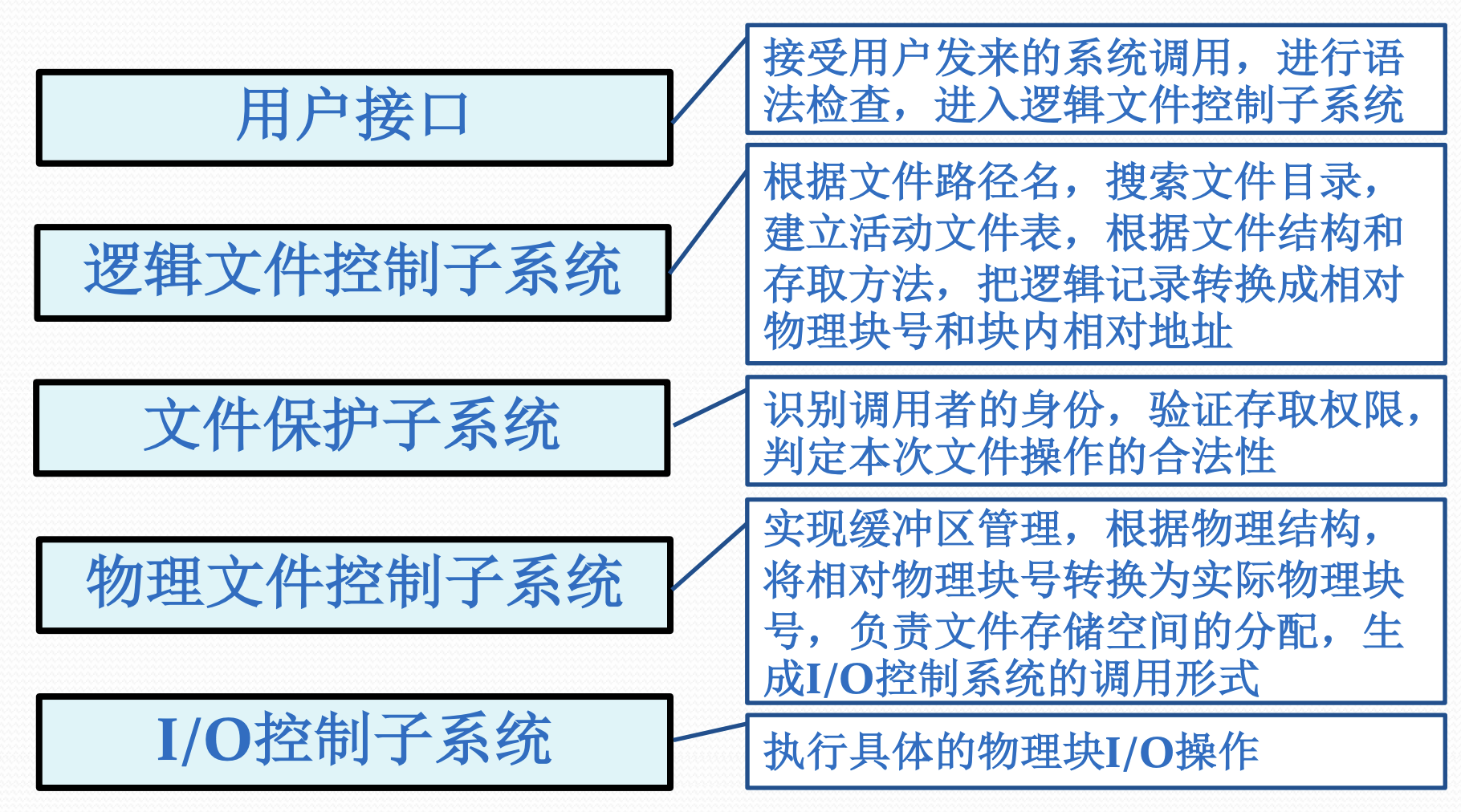
文件系统的功能
由于文件是一种抽象的概念, 因此文件系统的功能也要分层次考虑
面向用户的功能
- 文件的按名存取 (这也是文件系统的主要目的)
- 文件的共享和保护
- 文件的操作和使用
为了构建可靠的文件系统, OS必须考虑的事情是
- 文件目录的建立和维护
- 存储空间的分配和回收
- 数据的保密和保护
- 监督用户存取和修改文件的权限
- 实现在不同存储介质上信息的表示方 式、编址方法、存储次序,以及信息 检索等问题
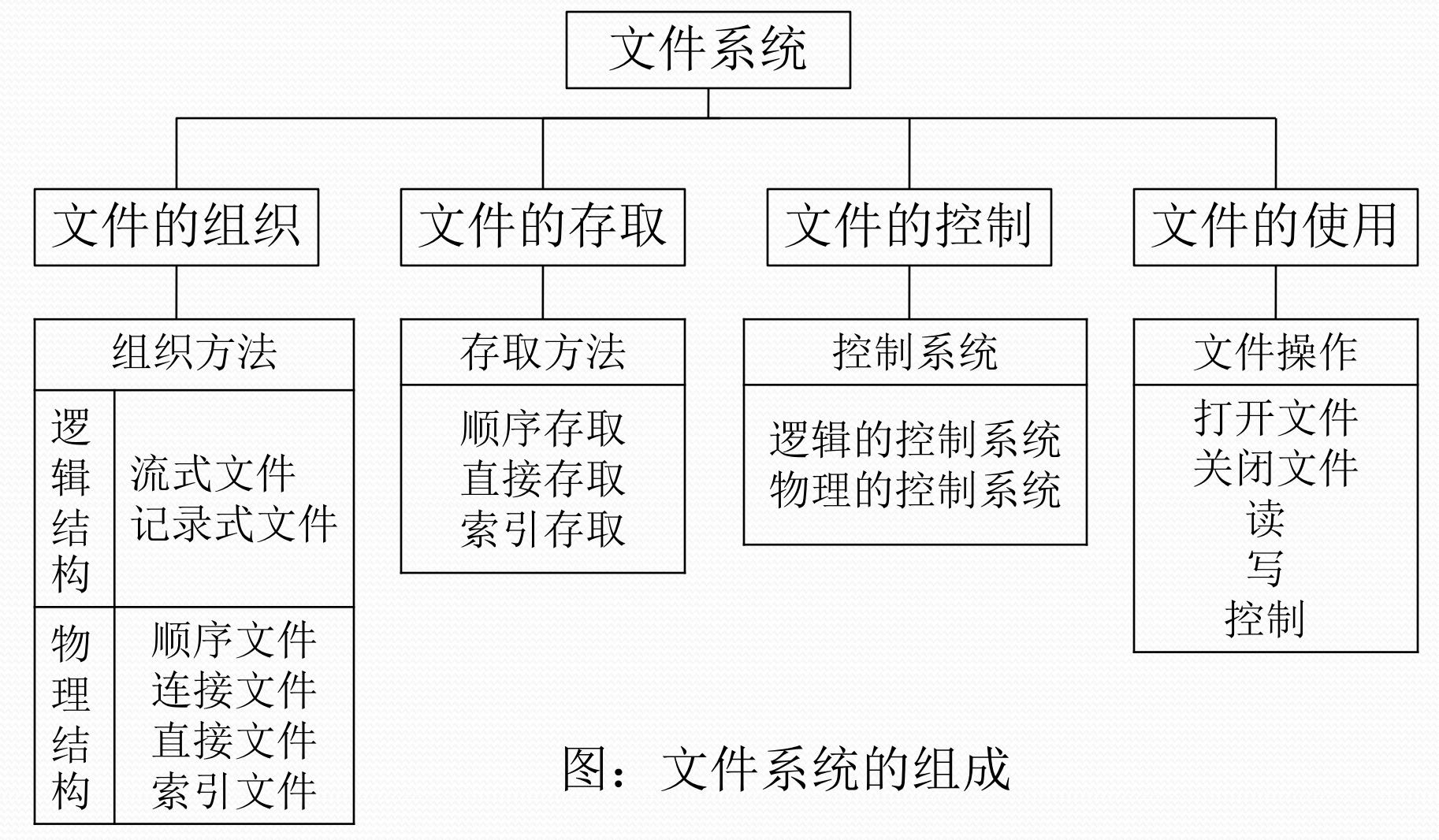
2. 文件的组织
2.1. 文件的存储
文件存储介质有磁带、光盘和磁盘
两个概念: 卷和块
卷 (Volume): 一个卷可以视为一个文件系统. 从设计的角度来讲, 一个Volume可以认为是一个虚拟存储设备(磁盘/光盘/磁带). 在Windows上, 一个物理磁盘实际上可以分为多个Volume, 每个Volume可以使用不同的文件系统(NTFS, FAT, etc.)
块 (Block): Block是存储器进行数据交换的最小单位. 早期的Block大小一半是512字节, 但是现代Block的大小在4kb~64kb之间
块为什么设计成这么大: 考虑多方面的统计学因素. 实际上, 块的大小很灵活. 同一存储介质的块大小一般相同, 也可以不同(这话说了就像没说)
块是连续存储的吗: 是也不是. 实际上, 块之间留有空隙. 考虑到如下的2点因素
- 设备读写时往往会进行机械操作, 为了确保安全并避免数据损坏,相邻的数据块之间需要留有足够的距离,以免机械部件运动产生干扰或碰撞。
- 某些外围设备可能需要识别不同块之间的分界点,以便正确地读取或写入数据。为了满足这种需求,相邻的数据块之间也会留有一定的间隙,以确保设备能够准确识别块的边界位置。
顺序存取存储设备的信息安排
磁带 & 光盘是典型的顺序存取存储设备
严格依赖信息的物理位置次 序进行定位和读写的存储设备
直接存取存储设备的信息安排
磁盘
它的每个物理记录有确定的位置和唯 一的地址,存取任何一个物理块所需 的时间几乎不依赖于此信息的位置
2.2. 文件的逻辑结构
逻辑文件
i.e.文件的逻辑结构. 也就是完全不管其物理结构的, 用户能够直观感受到的文件
分成两种形式
- 流式文件 (Stream File)
- 记录式文件 (Record File)
GPT: “判断一种文件是流式文件还是记录式文件,需要根据该文件所采用的文件格式和数据组织方式来进行分析。
通常情况下,流式文件是一种顺序型文件,其中数据按照固定的字节流顺序排列。在读写流式文件时,应用程序可以读取或写入任意长度的数据,但必须按照顺序进行,不能跳过或插入数据。
而记录式文件则通常将数据组织成若干个逻辑上的记录,每个记录由多个字段组成。在处理记录式文件时,应用程序通常需要对每个记录进行读取或写入操作,并且每个记录通常具有相同的长度或可变长度,由特定的记录分隔符进行分隔。
例如,在文本文件中,每个字符都被视为一个字节,它们按照顺序排列组成了一整个文件。因此,文本文件是一种典型的流式文件。而在数据库系统中,每个记录代表一个实体,例如一个人、一辆车或一张订单等等,每个记录由若干个字段组成,因此数据库中的数据通常是一种记录式文件。
总之,要判断一个文件是流式文件还是记录式文件,需要分析该文件所采用的文件格式和数据组织方式。”
直观的感受: 有结构的文件就是记录式文件, 无结构的文件就是流式文件
文件系统和数据库系统的区别
DBMS可以支持基于联系的查询 (因为数据库中的记录可以通过数据冗余形成某种联系). 但是文件系统不能支持基于联系的查询
2.3. 记录的成组与分解
这里的记录就是上文 记录式文件 的记录
给出非常愚蠢的定义: 若干个逻辑记录合并成一组,写入一个块叫记录的成组,每块中的逻辑记录数称为块因子
如何实现记录成组: 使用计算机科学中的经典想法——添加一个中间层(buffer)
- 记录的成组操作在输出缓冲区内进行, 凑满一块后才将缓冲区内的信息写到存储介质上
类似的, 先从存储介质上取出一个block, 再取出其中的一个记录, 这样的行为叫做记录的分解
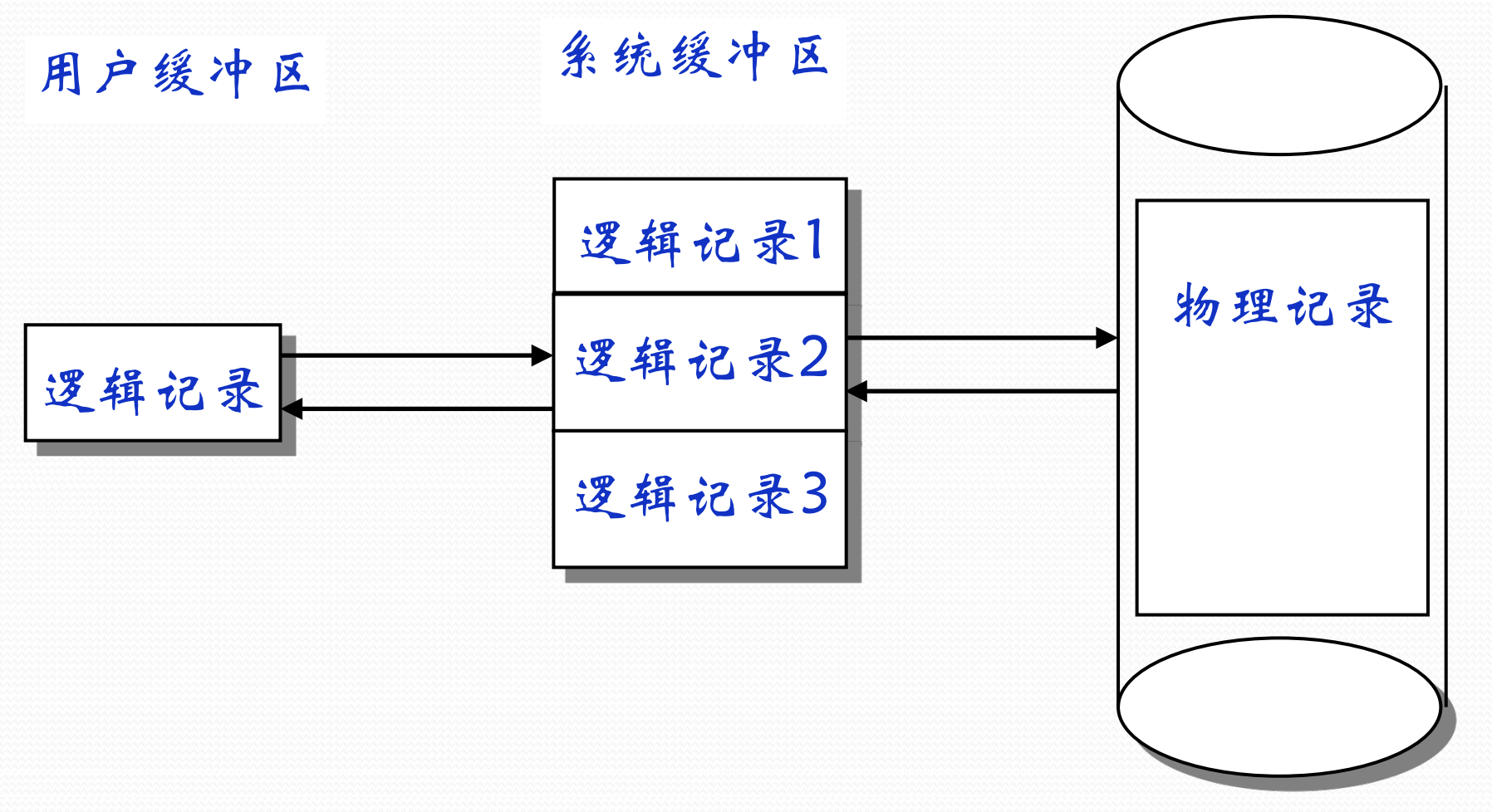
记录成组和分解的优点
trivially节省了存储空间 (考虑到存储设备一次性只能传一个block过来, 如果记录不成组的话, 一个block中便只能有一条记录, 是非常浪费的)trivially减少IO次数
当然也带来一些不足一提的副作用:
- 提前读: 读取一个逻辑记录时, 会将和它在一个block的一堆逻辑记录都带出来
- 推迟写: 写完一个逻辑记录后, 需要将它后续的一堆逻辑记录都写完并构成一个完整的block才能写入存储设备
2.4. 文件的物理结构
文件的物理结构 $\iff$ 物理文件
从设计的角度来讲, 文件的物理结构影响文件系统的性能
顺序文件
$O(n)$
将逻辑上连续的文件存放到存储介质中相邻的block中, 以这样存储方式进行存储的文件叫做顺序文件(连续文件). 一些典型的例子就是系统文件和批处理文件(bat, sh)
trivially, 顺序文件的存储是很快的, 但是任何修改都会显得很麻烦(可能会影响相邻的文件), 同时在存储之前必须先知道文件的大小. 因此从设计的角度来讲, 多读少写的文件更加适合以这样的方式存储. 系统文件就是很典型的例子.
从设计的角度来讲, 顺序文件的存储很像C语言里的数组.
连接文件
$O(n)$, 或者叫串联文件
愚蠢的又平凡定义: 用一个叫连接块的东西, 来指向下一个物理块 (因为物理块是最小单位). 同时如果连接块的value为0, 它就是结尾
我真不理解为什么要设置这么多混淆的, 矛盾的, 愚蠢的, 不可复用的定义.
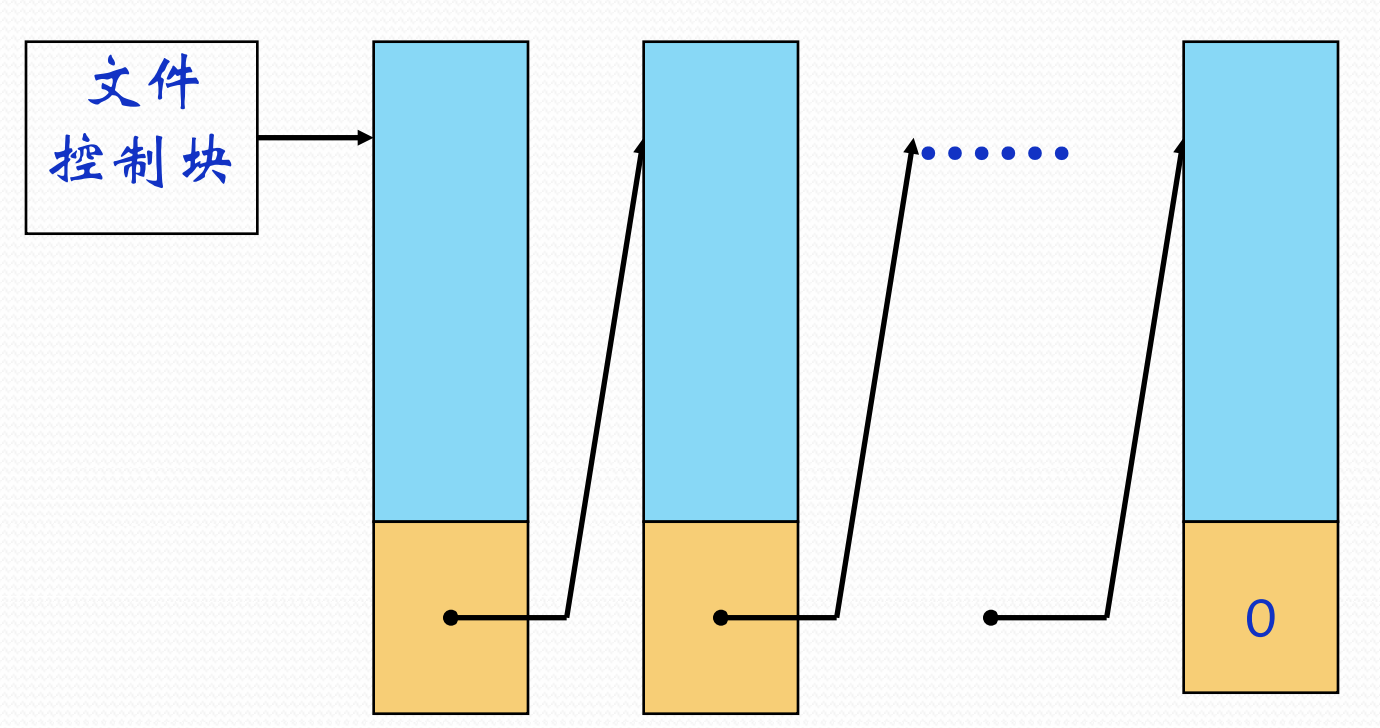
从设计的角度来讲, 顺序文件的存储很像C语言里的链表. 它的存储, 修改, 删除都非常方便, 但是不方便的是一切涉及到读的操作. 并且由于其物理结构的性质, 只能顺序存取
直接文件
$O(1)$, 或者叫散列文件
通过计算记录的关键字建立与其物理存储地址之间的对应关系, 常常使用Hash散列. 那么很明显, 这样的文件应该具有Hash散列数据的性质.
为了解决Hash函数中不可避免的冲突, 这里引入几个无比trivial又中二的称呼:
- 拉链法
- 循环探查法
- 二次散列法
- 溢出区法
索引文件
$O(1)$, 基本思想: 建立一个中间层
索引文件在文件存储器上分两个区
- 索引区
- 数据区
访问索引文件需两步操作
- 第一步查找索引表
- 第二步获得记录物理地址
为每个文件建立了一张索引表,其中,每个表目包含一个记录的键(或逻辑记录号)及其存储地址. 这样的设计是我很欣赏的.
在Unix下, 可以用stat <PATH> 来查看文件的索引结构

3. 文件目录
3.1. 目录结构
文件目录是实现文件的 按名存取 的关键数据结构. 为了解决不同用户文件的 命名冲突 问题,通常在文件系统中采用多级目录.
具体来说, Unix系统中, 通过 目录项 这一数据结构实现文件系统的按名存取功能.
比较重要的一点是, 文件目录需要永久保存,因此也组织成文件存放在磁盘上,称目录文件
- 一级目录结构: 想象一下所有文件存储在一个目录下
- 二级目录结构: 底层目录用于存储不同的用户信息, 高级目录用户存储每个用户的文件 (很有点RBAC的感觉)
- 树形目录结构
值得注意的是, 在树形目录结构中, 一个文件的全名包括从根目录开始到文件为止, 通路上遇到的所有子目录路径, 又称为路径名
也就是说路径名不是路径的名字, 是这个文件的名字
值得区分的是, 目录和路径是不一样的概念:
- 目录(Directory)是指在文件系统中用于组织和管理文件和子目录的一种数据结构。每个目录都可以包含若干个文件和子目录,并且可以通过目录索引来访问其中的内容。在Unix和Linux等操作系统中,目录通常用一个特殊的文件来表示,其中存储了目录下的所有文件和子目录信息。
- 路径(Path)是指用于标识文件或目录在文件系统中位置的字符串。通常以根目录(如“/”)为起点,逐级列出该文件或目录所在的目录名,直到最后一级为止。例如,“/usr/local/bin/test.sh”就是一个典型的文件路径,表示test.sh文件位于/usr/local/bin目录下。
文件系统用**目录来组织文件**
3.2. 文件目录的管理
这里前面一部分主要讲一些指令, trivial
树形文件系统存在的一个问题是:当一个文件经过许多目录节点时, 使用很不方便; 系统在沿路径查找目录时, 往往要多次访问文件存储器,使访问速度大大减慢.
从设计的角度来讲, 一种有效办法是把常用和正在使用的那些文件目录复制进主存, 这样, 既不增加太多的主存开销. 又可明显减少目录查找时间.
为了实现如上的设计, 设计一种新的中间层, 叫做活动文件表, 抽象出文件的两种平凡的操作:
- 打开: 系统可以为每个用户进程建立一张活动文件表,当用户使用一个文件之前,先通过 打开 操作,把该文件有关目录信息复制到指定主存区域, 有关信息填入活动文件表, 以建立用户进程和该文件索引的联系. (这也就是大文件打开时间会比较长, 特别大的文件打开时可能会死机)
- 关闭: 当不再使用该文件时,使用 关闭, 切断用户进程和这个文件的联系. 同时, 若该目录已被修改过,则应更新辅存中对应的文件目录
4. 文件共享, 保护和保密
从信息安全 (CIA) 的角度, 文件的设计需要考虑如下几点
- 文件共享: 是指不同用户共同使用某些文件 (Accessibility)
- 文件保护: 是指防止文件被破坏 (Integrity)
- 文件保密: 则是指防止文件及其内容被其他用户窃取 (Confidentiality)
4.1. 共享
很自然地, 操作系统必须为文件共享提供并发控制. 这一点我们会在并发部分仔细谈论.
4.2. 保护
常用的文件保护办法
文件副本
- 动态多副本技术: 是在多个介质上维持同一内容的文件,并且在更新内容时同时进行
- 转储, 备份与恢复: 定时把文件复制转储到其它介质上,当某介质上出现故障时,复原转储文件
文件存取矩阵与文件存取表
也就是信息安全课上讲的那个
实际上限制了用户能访问文件的部分权限, 是一种RBAC
设计文件属性

rwx, user等信息便是非常典型的文件属性. 使用chmod, chgrp, chown等指令便可以修改对应的文件属性.
5. 文件的使用
5.1. 存取方法
文件存取方法是操作系统为用户程序提供的使用文件的技术和手段, 在某种程度上依赖于文件的物理结构.
顺序存取
$O(n)$
指的是像磁带这种存储设备上, 想要读或者写某一个文件, 必须从头扫描找到它.
直接存取
$O(1)$, 也叫做随机存取
指的是按地址索引. 可以直接访问存储空间内任何一处的数据. 典型的例子就是磁盘上的文件, 既可以随机存取, 又可以顺序存取
索引存取
$O(1)$, idk, or maybe $O(\log n)$
要查表. 一般按照二分查找等方法索引.
5.2. 文件的使用
用户通过两类接口来与文件系统相联系.
- 文件操作命令: cp, mv, find, mkdir, etc.
- 文件类系统调用: 建立, 打开, 读/写, 定位, 关闭, 撤销
建立文件: 在相应设备上建立一个文件目录项, 为文件分配第一个物理块, 在活动文件表中申请一个项, 登记有关目录信息, 并返回一个文件句柄
撤销文件: 若文件没有关闭, 先关闭文件; 若为共享文件, 进行联访处理; 在目录文件中删去相应目录项; 释放文件占用的文件存储空间
打开文件: 将活动文件表中该文件的“当前 使用用户数”减1;若此值为0,则收回此活 动文件表;完成“推迟写” ;若活动文件表 目内容已被改过,则应先将表目内容写回文 件存储器上相应表目中,以使文件目录保持 最新状态

而open的返回值是一个整数类型的文件描述符 (File Descriptor)
读/写文件: 按文件句柄从活动文件表中找到该文件的目录项信息; 根据目录项指出的该文件的逻辑和物理组织方式, 把相关逻辑记录转换成物理块
定位文件
6. 文件系统实现
6.1. 辅存空间管理
主要是碎片管理: 由于被多用户共享, 文件碎片经常出现.
解决方法: 定期地对文件重新组织,让其存放在连续存储区中. (trivial but necessary)
辅存空间的分配方式
- 连续分配:存放在辅存空间连续存储区中 (连续的物理块号) 优点是顺序访问时速度快,管理较为简单, 但为了获得足够大的连续存储区,需定时进行‘碎片’整理
- 非连续分配:动态分配给若干扇区或簇(几 个连续扇区),不要求连续优点是辅存空间管理效率高,便于文件动态增长和收缩
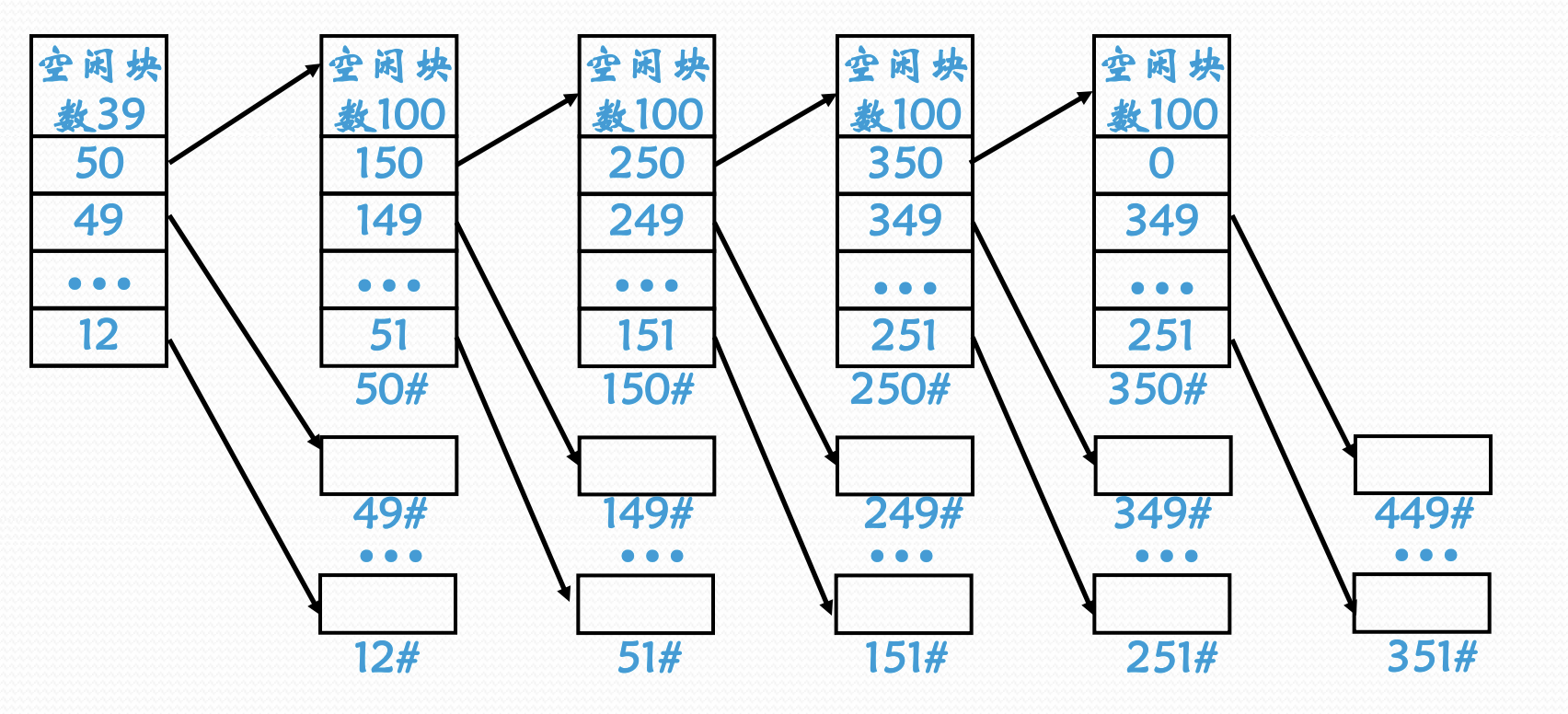
空闲块的管理
- 位示图法: FAT12文件系统
- 空闲块成组连接法: 使用如下图的方式将空闲块组织起来
6.2. 文件系统的实现层次